前置条件
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
需要安装 cuda toolkit,具体可以参考官网
1 | apt-get install -y nvidia-container-toolkit |
配置 runtime
使用 nvidia-ctk 配置, 官方推荐命令配置:
1 | # docker |
修改的 是 /etc/docker/daemon.json 和 /etc/containerd/config.toml 文件
1 | "default-runtime": "nvidia", |
以及1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
SystemdCgroup = true
测试 containerd 的默认 runtime_name 还是 runc, 修改为 nvidia;
1 | [plugins."io.containerd.grpc.v1.cri".containerd] |
docker
未安装 nvidia-container-toolkit 时1
2root@debian:~# docker run --rm --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
安装后
1 |
|
k8s
需要先安装 nvidia 插件
或者使用 https://github.com/NVIDIA/gpu-operator (可以自动安装驱动)
1 | apiVersion: apps/v1 |
部署完,看日志有报错1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47# kubectl logs -f -n kube-system nvidia-device-plugin-daemonset-fb7lc
I0618 07:00:59.142415 1 main.go:178] Starting FS watcher.
I0618 07:00:59.142533 1 main.go:185] Starting OS watcher.
I0618 07:00:59.143158 1 main.go:200] Starting Plugins.
I0618 07:00:59.143180 1 main.go:257] Loading configuration.
I0618 07:00:59.144107 1 main.go:265] Updating config with default resource matching patterns.
I0618 07:00:59.144327 1 main.go:276]
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": false,
"mpsRoot": "",
"nvidiaDriverRoot": "/",
"gdsEnabled": false,
"mofedEnabled": false,
"useNodeFeatureAPI": null,
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": [
"envvar"
],
"deviceIDStrategy": "uuid",
"cdiAnnotationPrefix": "cdi.k8s.io/",
"nvidiaCTKPath": "/usr/bin/nvidia-ctk",
"containerDriverRoot": "/driver-root"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {}
}
}
I0618 07:00:59.144338 1 main.go:279] Retrieving plugins.
I0618 07:00:59.145558 1 factory.go:104] Detected NVML platform: found NVML library
I0618 07:00:59.145613 1 factory.go:104] Detected non-Tegra platform: /sys/devices/soc0/family file not found
I0618 07:00:59.161587 1 server.go:216] Starting GRPC server for 'nvidia.com/gpu'
I0618 07:00:59.162167 1 server.go:147] Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
I0618 07:00:59.176954 1 server.go:154] Registered device plugin for 'nvidia.com/gpu' with Kubelet
我的原因是 containerd 的默认 runtime 是 runc 改成 nvidia 后重启 containerd 及插件容器
1 | kubectl logs -f -n kube-system nvidia-device-plugin-daemonset-j4jdg |
describe node 节选
1 | Allocatable: |
我这个机器上只有一块显卡, k8s 的 GPU 调度申请的显卡只能为整数。 可以使用 vGPU 或者 MIG 虚拟化,但需要显卡支持
测试
1 | apiVersion: v1 |
Running 期间,其他的 GPU 容器 Pending , 日志1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
kubectl logs -f gpu-demo-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
GPU 0: NVIDIA GeForce GTX 950M (UUID: GPU-8eef98eb-0dbc-be7e-99d4-5992e5ad79e0)
Wed Jun 19 07:45:41 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| N/A 46C P0 N/A / N/A | 3MiB / 4096MiB | 2% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
直接使用 gpu-operator
k8s 上可以直接使用 gpu-operator,自动安装 驱动,cuda 以及 plugin
驱动支持的操作系统有限,可以先去查看 https://catalog.ngc.nvidia.com/orgs/nvidia/containers/driver/tags
当前使用的 gpu-operator-v24.3.0, 最新安装的 ubuntu-server 22.04 版本
使用到的镜像,内网环境可能需要提前准备好镜像包,仅容器内有效, nvidia-driver-daemonset 容器删除重建后会重新编译 驱动。所以最好提前在服务器上安装好驱动及插件。
1 | nvcr.io/nvidia/cloud-native/gpu-operator-validator v24.3.0 |
使用 helm 安装1
2
3
4
5
6helm repo add nvidia https://nvidia.github.io/gpu-operator
helm repo update
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator
执行完成后生成如下 pod
1 | gpu-operator gpu-feature-discovery-zd5qc 1/1 Running 0 69s |
这些 Pod 是 gpu-operator 组件的一部分,每个 Pod 执行特定的任务以确保 Kubernetes 集群能够正确地检测和使用 GPU。以下是每个 Pod 的作用:
gpu-feature-discovery:
- Pod 名称:
gpu-feature-discovery-zd5qc - 作用:检测节点上的 GPU 相关特性,并将这些特性报告给 Kubernetes,以便调度器能够根据这些特性做出更智能的调度决策。
- Pod 名称:
node-feature-discovery:
- Pod 名称:
gpu-operator-1719300178-node-feature-discovery-gc-c4b5bb74pcs28gpu-operator-1719300178-node-feature-discovery-master-664c5pbsjgpu-operator-1719300178-node-feature-discovery-worker-q544b
- 作用:检测节点的硬件和软件特性,并将这些特性标签添加到节点上,以帮助 Kubernetes 调度器做出更好的调度决策。
- Pod 名称:
gpu-operator:
- Pod 名称:
gpu-operator-ff9fb8679-w5xqk - 作用:管理和部署 GPU 相关的组件和资源,包括驱动程序、工具和插件。
- Pod 名称:
nvidia-container-toolkit-daemonset:
- Pod 名称:
nvidia-container-toolkit-daemonset-vn9dv - 作用:提供在容器中使用 NVIDIA GPU 的支持,包含 NVIDIA Container Runtime。
- Pod 名称:
nvidia-cuda-validator:
- Pod 名称:
nvidia-cuda-validator-fv8vc - 作用:验证 CUDA 的安装和功能,确保 GPU 资源可以正确使用。
- Pod 名称:
nvidia-dcgm-exporter:
- Pod 名称:
nvidia-dcgm-exporter-kfth8 - 作用:从 NVIDIA Data Center GPU Manager (DCGM) 收集 GPU 相关的监控数据,并将其导出到 Prometheus 格式。
- Pod 名称:
nvidia-device-plugin-daemonset:
- Pod 名称:
nvidia-device-plugin-daemonset-bc9q9 - 作用:为 Kubernetes 提供 NVIDIA GPU 的插件,使得 GPU 资源可以在 Kubernetes 中使用和管理。
- Pod 名称:
nvidia-operator-validator:
- Pod 名称:
nvidia-operator-validator-lfkl2 - 作用:验证 GPU Operator 组件的安装和功能,确保所有组件正确运行。
- Pod 名称:
nvidia-driver-daemonset:
- Pod 名称:
nvidia-driver-daemonset-ts2bf - 作用:在每个节点上安装和管理 NVIDIA GPU 驱动程序。
- Pod 名称:
这些 Pod 协同工作,确保 GPU 资源在 Kubernetes 集群中能够被正确检测、使用和管理。
编辑 kubectl edit clusterpolicies.nvidia.com, 可以看到默认的组件
1 | ccManager: |
查看 node 信息
1 | kubectl describe node |
验证1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32root@test-ThinkPad-L14-Gen-2:~# kubectl logs -f -n gpu-operator nvidia-operator-validator-lh5n2 -c toolkit-validation
time="2024-06-26T16:00:53Z" level=info msg="version: 0fe1e8db, commit: 0fe1e8d"
Wed Jun 26 16:00:53 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce MX450 On | 00000000:01:00.0 Off | N/A |
| N/A 47C P8 N/A / 10W | 0MiB / 2048MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
root@test-ThinkPad-L14-Gen-2:~# kubectl logs -f -n gpu-operator nvidia-operator-validator-lh5n2 -c cuda-validation
time="2024-06-26T16:00:55Z" level=info msg="version: 0fe1e8db, commit: 0fe1e8d"
time="2024-06-26T16:00:55Z" level=info msg="pod nvidia-cuda-validator-zpxn7 is curently in Pending phase"
time="2024-06-26T16:01:00Z" level=info msg="pod nvidia-cuda-validator-zpxn7 is curently in Running phase"
time="2024-06-26T16:01:05Z" level=info msg="pod nvidia-cuda-validator-zpxn7 have run successfully"
root@test-ThinkPad-L14-Gen-2:~# kubectl logs -f -n gpu-operator nvidia-operator-validator-lh5n2 -c plugin-validation
time="2024-06-26T16:01:07Z" level=info msg="version: 0fe1e8db, commit: 0fe1e8d"
root@test-ThinkPad-L14-Gen-2:~# kubectl logs -f -n gpu-operator nvidia-operator-validator-lh5n2
Defaulted container "nvidia-operator-validator" out of: nvidia-operator-validator, driver-validation (init), toolkit-validation (init), cuda-validation (init), plugin-validation (init)
all validations are successful
同样执行上面的两个 pod
1 | kubectl logs gpu-pod |
遇到的问题
gcc 版本不对应,安装失败1
2
3
4
5warning: the compiler differs from the one used to build the kernel
The kernel was built by: x86_64-linux-gnu-gcc-12 (Ubuntu 12.3.0-1ubuntu1~22.04) 12.3.0
You are using: cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
cc: error: unrecognized command-line option '-ftrivial-auto-var-init=zero'
make[3]: *** [scripts/Makefile.build:251: /usr/src/nvidia-550.54.15/kernel/nvidia/nv.o] Error 1
解决方法
1 | FROM nvcr.io/nvidia/driver:550.54.15-ubuntu22.04 |
重新构建镜像1
2
3docker build -t mydriver .
docker save -o mydriver.tar mydriver
ctr -i k8s.io images import mydriver.tar
修改 daemonset 使用 mydriver 镜像
prometheus 监控数据
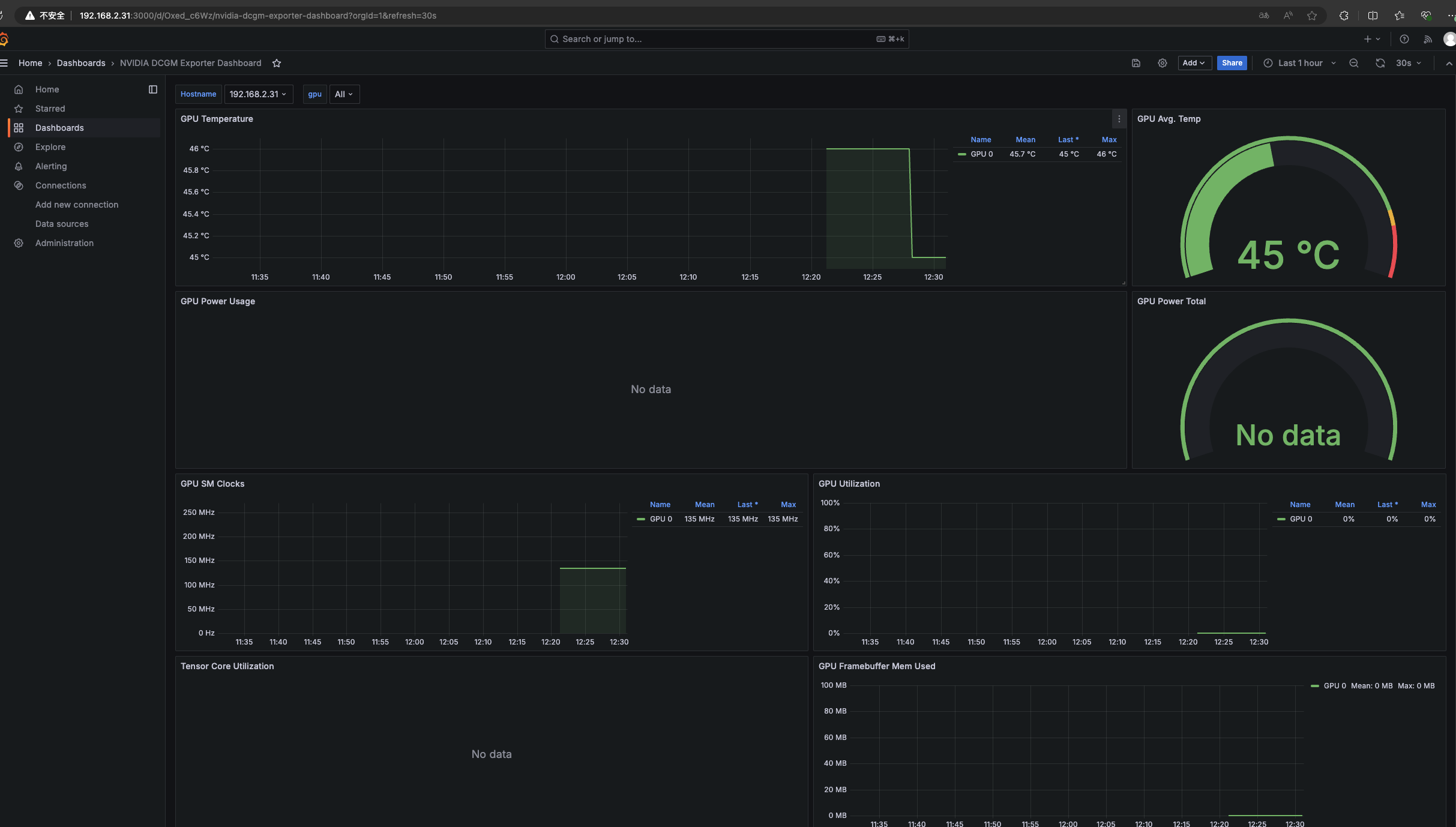
可使用的面板之一 https://grafana.com/grafana/dashboards/21362-nvidia-dcgm-exporter-dashboard/
id: 21362
https://github.com/NVIDIA/dcgm-exporter
nvidia-dcgm-exporter 数据展示
curl nvidia-dcgm-exporter:port/metrics 当前版本的所有指标
1 | # HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz). |
指标解释
nvidia-dcgm-exporter 提供了许多关于 GPU 的关键性能指标,这些指标可以帮助监控和诊断 GPU 的健康和性能。以下是你提到的每个指标的详细解释:
DCGM_FI_DEV_SM_CLOCK
- 描述: SM(Streaming Multiprocessor)时钟频率,单位为 MHz。
- 类型:
gauge(测量一个特定时间点的值) - 示例:
300表示 SM 时钟频率为 300 MHz。
DCGM_FI_DEV_MEM_CLOCK
- 描述: 内存时钟频率,单位为 MHz。
- 类型:
gauge - 示例:
405表示内存时钟频率为 405 MHz。
DCGM_FI_DEV_MEMORY_TEMP
- 描述: 显卡内存温度,单位为摄氏度。
- 类型:
gauge - 示例:
0表示当前内存温度为 0°C。
DCGM_FI_DEV_GPU_TEMP
- 描述: GPU 温度,单位为摄氏度。
- 类型:
gauge - 示例:
43表示当前 GPU 温度为 43°C。
DCGM_FI_DEV_PCIE_REPLAY_COUNTER
- 描述: PCIe 重试次数总计。
- 类型:
counter(累积值,随着时间增加) - 示例:
0表示没有发生 PCIe 重试。
DCGM_FI_DEV_GPU_UTIL
- 描述: GPU 利用率,单位为百分比。
- 类型:
gauge - 示例:
0表示当前 GPU 利用率为 0%。
DCGM_FI_DEV_MEM_COPY_UTIL
- 描述: 内存复制利用率,单位为百分比。
- 类型:
gauge - 示例:
0表示当前内存复制利用率为 0%。
DCGM_FI_DEV_ENC_UTIL
- 描述: 编码器利用率,单位为百分比。
- 类型:
gauge - 示例:
0表示当前编码器利用率为 0%。
DCGM_FI_DEV_DEC_UTIL
- 描述: 解码器利用率,单位为百分比。
- 类型:
gauge - 示例:
0表示当前解码器利用率为 0%。
DCGM_FI_DEV_XID_ERRORS
- 描述: 最近一次 XID 错误的值。
- 类型:
gauge - 示例:
0表示没有 XID 错误。
DCGM_FI_DEV_FB_FREE
- 描述: 剩余显存,单位为 MiB。
- 类型:
gauge - 示例:
1863表示当前剩余显存为 1863 MiB。
DCGM_FI_DEV_FB_USED
- 描述: 已使用显存,单位为 MiB。
- 类型:
gauge - 示例:
0表示当前已使用显存为 0 MiB。
DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL
- 描述: NVLink 总带宽计数,所有通道的总和。
- 类型:
counter - 示例:
0表示 NVLink 带宽总计为 0。
DCGM_FI_DEV_VGPU_LICENSE_STATUS
- 描述: vGPU 许可证状态。
- 类型:
gauge - 示例:
0表示 vGPU 许可证状态为 0(无许可证)。
这些指标提供了关于 GPU 性能和健康的详细信息,帮助你实时监控和分析 GPU 的状态。在 Prometheus 中抓取这些指标后,可以在 Grafana 等可视化工具中创建仪表板,监控这些关键指标.
测试搭建
prometheus.yml1
2
3
4
5
6
7
8
9
10
11
12
13global:
scrape_interval:
external_labels:
monitor: 'codelab-monitor'
# 这里表示抓取对象的配置
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s #重写了全局抓取间隔时间,由15秒重写成5秒
static_configs:
- targets: ['localhost:9090']
- job_name: 'nvidia-metrics'
static_configs:
- targets: ['192.168.2.31:30975']
docker
1 | docker run -p 3000:3000 --name grafana \ |
使用上面的模版
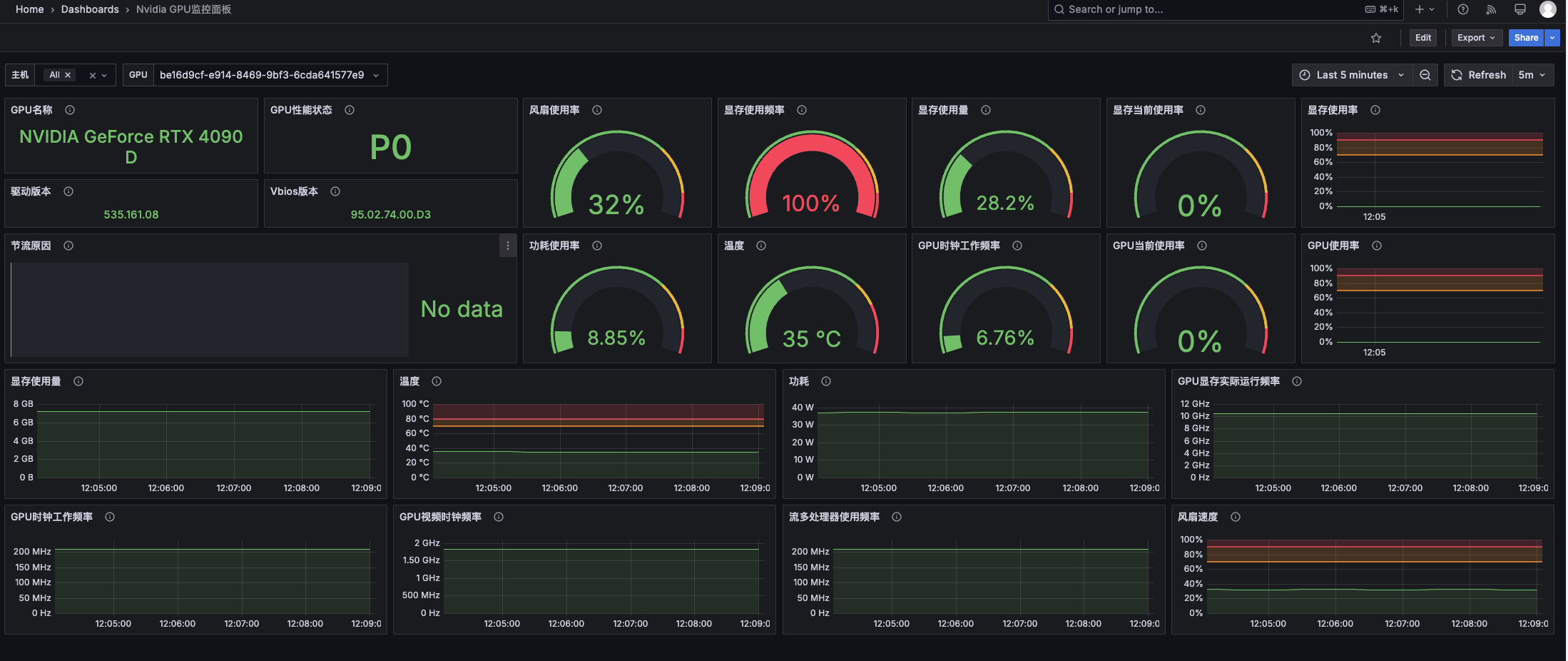
更换面板
项目 https://github.com/utkuozdemir/nvidia_gpu_exporter
面板: https://grafana.com/grafana/dashboards/14574-nvidia-gpu-metrics/
面板id: 14574 中文 20622
1 | $ docker run -d \ |
效果查看