CPU它承担了所有的计算任务,进程是指程序的一次执行,线程是CPU的基本调度单位。- 进程的内存空间是共享的,每个线程都可以使用这些共享内存,
- 一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存,”互斥锁”(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域
- “互斥锁”(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域
- 某些内存区域,只能供给固定数目的线程使用,”信号量”(Semaphore),用来保证多个线程不会互相冲突
概念
进程就是操作系统中执行的一个程序,操作系统以进程为单位分配存储空间,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据,操作系统管理所有进程的执行,为它们合理的分配资源。进程可以通过 fork 或 spawn 的方式来创建新的进程来执行其他的任务,不过新的进程也有自己独立的内存空间,因此必须通过进程间通信机制(IPC,Inter-Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存区等。
一个进程还可以拥有多个并发的执行线索,简单的说就是拥有多个可以获得 CPU 调度的执行单元,这就是所谓的线程。由于线程在同一个进程下,它们可以共享相同的上下文,因此相对于进程而言,线程间的信息共享和通信更加容易。当然在单核 CPU 系统中,真正的并发是不可能的,因为在某个时刻能够获得 CPU 的只有唯一的一个线程,多个线程共享了 CPU 的执行时间
同步与异步
同步: 发出一个功能调用时,在没得到结果前,该调用 不返回或继续执行后续操作
异步: 发出一个功能调用时,在没得到结果前,可以继续执行后续操作。 调用的返回不受控制
异步是目的,多线程是实现这个目的的方法
阻塞和非阻塞
阻塞和非阻塞 主要是程序(线程) 等待消息 通知时的状态有关。
阻塞 : 调用结果没返回前,当前线程被挂起
非阻塞 :调用不能得到结果前,该调用不会阻塞当前线程
并发并行
并发 :单核 cpu 多线程,一个时间段 只有一个线程,其他线程处于挂起状态。多个线程共享了 CPU 的执行时间
并行 :多核 cpu , 一个 cpu 执行一个线程时,另一个 cpu 同时执行另一个线程。这两个线程间不抢占 cpu 资源,可同时进行
线程
线程 本质上是 进程中一段并发运行的代码,所以 线程需要 操作系统投入 cpu 资源来运行和调度(Python 计算密集型,gil锁,效率反而会低)
多线程优点 : 依然顺序执行,编程简单
多线程缺点 : 上下文切换的额外负担、线程间共享变量会出现死锁
同步/异步/阻塞/非阻塞
同步阻塞 :效率低
同步非阻塞 :需要在两种状态来回切换
异步阻塞 : 不是处理消息时阻塞,而是等待消息阻塞。不做其他任务处理
异步非阻塞 :效率高
锁
原子操作就是操作不可分
比如 i++ 就不是一个原子操作,因为它是 3 个原子操作组合而成的:
读取 i 的值;
计算 i+1;
写入新的值。
像这样的操作,在多线程 + 多核环境会造成竞争条件
i++这段程序访问了共享资源,也就是变量i,这种访问共享资源的程序片段我们称为临界区
解决竞争条件有很多方案,一种方案就是不要让程序同时进入临界区,这个方案叫作互斥
还有一些方案旨在避免竞争条件,比如 `ThreadLocal、 cas 指令以及乐观锁等
cas
比如想用 cas 更新i的值,而且知道i是 100,想更新成101。那么就可以这样做:1
2
3
4
5
6
7读取i
计算i+1
cas操作:比较期望值i和i的真实值的值是否相等,如果是,更新目标值
cas(&i, 100, 101)
1 | while(!cas(&i, i, i+1)){ |
tas 指令的目标是设置一个内存地址的值为 1,它的工作原理和 cas 相似。首先比较内存地址的数据和 1 的值,如果内存地址是 0,那么把这个地址置 1。如果是 1,那么失败。
所以你可以把 tas 看作一个特殊版的cas,可以这样来理解:
复制代码
tas(&lock) {
return cas(&lock, 0, 1)
}
锁
锁(lock),目标是实现抢占(preempt)。就是只让给定数量的线程进入临界区。锁可以用tas或者cas来实现。
0 表示没进入临界区, 1 代表目前有线程进入临界区1
2
3
4
5
6
7
8
9int lock = 0;
enter(){
while( !cas(&lock, 0, 1) ) {
// 什么也不做
}
}
leave(){
lock = 0;
}
自旋锁
这段代码不断在 CPU 中执行指令,直到锁被其他线程释放。这种情况线程不会主动释放资源,我们称为自旋锁。1
2
3
4
5enter(){
while( !cas(&lock, 0, 1) ) {
// 什么也不做
}
}
wait 操作
wait 操作,主动触发 Context Switch。这样就解决了 CPU 消耗的问题。但是触发 Context Switch 也是比较消耗成本的事情
1 | enter(){ |
生产者消费者模型
wait 是一个生产者,将当前线程挂到一个等待队列上,并休眠。notify 是一个消费者,从等待队列中取出一个线程,并重新排队
信号量
当lock初始值为 1 的时候,这个模型就是实现互斥(mutex)。如果 lock 大于 1,那么就是同时允许多个线程进入临界区。这种方法,我们称为信号量(semaphore)。
死锁问题
在并行的时候,如果两个线程互相等待对方获得的锁,就会发生死锁
分布式锁
比如 Redis 的 setnx 指令,Zookeeper 的节点操作等等
乐观锁
eg: Git
就是每次更新的发起方,需要明确地知道想从多少版本更新到多少版本1
2
3cas(&version, 100, 108); // 成功
cas(&version, 100, 106); // 失败,因为version是108
先更新的人被采纳,后更新的人负责解决冲突
线程调度的方法
- 先到先服务
- 短作业优先
- 优先级队列
- 抢占
- 多级队列模型
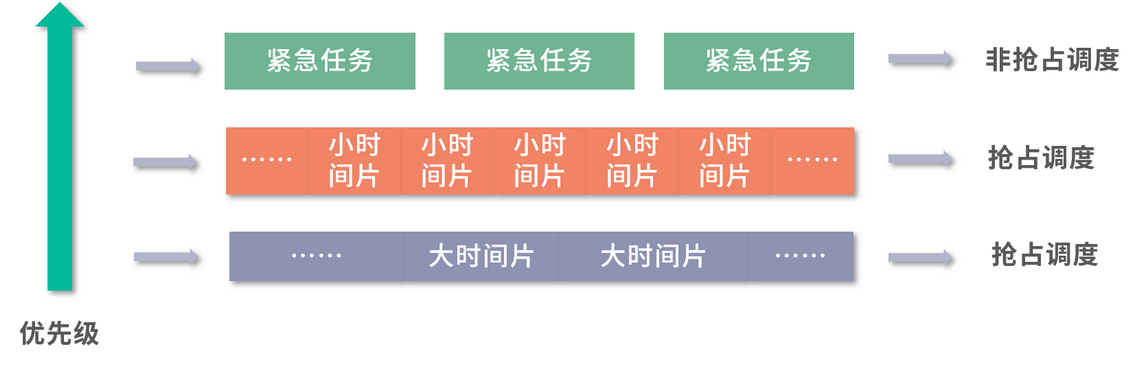
紧急任务仍然走高优队列,非抢占执行。普通任务先放到优先级仅次于高优任务的队列中,并且只分配很小的时间片;如果没有执行完成,说明任务不是很短,就将任务下调一层。下面一层,最低优先级的队列中时间片很大,长任务就有更大的时间片可以用。通过这种方式,短任务会在更高优先级的队列中执行完成,长任务优先级会下调,也就类似实现了最短作业优先的问题。
实际操作中,可以有 n 层,一层层把大任务筛选出来。 最长的任务,放到最闲的时间去执行。要知道,大部分时间 CPU 不是满负荷的
非抢占的先到先服务的模型是最朴素的,公平性和吞吐量可以保证。但是因为希望减少用户的平均等待时间,操作系统往往需要实现抢占。操作系统实现抢占,仍然希望有优先级,希望有最短任务优先。
但是这里有个困难,操作系统无法预判每个任务的预估执行时间,就需要使用分级队列。最高优先级的任务可以考虑非抢占的优先级队列。 其他任务放到分级队列模型中执行,从最高优先级时间片段最小向最低优先级时间片段最大逐渐沉淀。这样就同时保证了小任务先行和高优任务最先执行
进程间通信的方式
1. 管道
1 | 进程1 > namedpipe |
管道的核心是不侵入、灵活,不会增加程序设计负担,又能组织复杂的计算过程
2. 本地内存共享
Linux 内存共享库的实现原理是以虚拟文件系统的形式,从内存中划分出一块区域,供两个进程共同使用。看上去是文件,实际操作是内存。
共享内存的方式,速度很快,但是程序不是很好写,因为这是一种侵入式的开发,也就是说你需要为此撰写大量的程序。比如如果修改共享内存中的值,需要调用 API。如果考虑并发控制,还要处理同步问题等。因此,只要不是高性能场景,进程间通信通常不考虑共享内存的方式。
3. 本地消息/队列
一种是用消息队列——现代操作系统都会提供类似的能力。Unix 系可以使用 POSIX 标准的 mqueue。另一种方式,就是直接用网络请求,比如 TCP/IP 协议,也包括建立在这之上的更多的通信协议
4. 远程调用
远程调用(Remote Procedure Call,RPC)是一种通过本地程序调用来封装远程服务请求的方法。
程序员调用 RPC 的时候,程序看上去是在调用一个本地的方法,或者执行一个本地的任务,但是后面会有一个服务程序(通常称为 stub),将这种本地调用转换成远程网络请求。 同理,服务端接到请求后,也会有一个服务端程序(stub),将请求转换为一个真实的服务端方法调用
RPC 真正的缺陷是增加了系统间的耦合。当系统主动调用另一个系统的方法时,就意味着在增加两个系统的耦合。长期增加 RPC 调用,会让系统的边界逐渐腐化
5. 消息队列
一个系统订阅了另一个系统的事件,那么将来无论谁提供同类型的事件,自己都可以正常工作。系统依赖的不是另一个系统,而是某种事件。如果哪天另一个系统不存在了,只要事件由其他系统提供,系统仍然可以正常运转。
消息队列是一种耦合度更低,更加灵活的模型。但是对系统设计者的要求也会更高,对系统本身的架构也会有一定的要求。具体场景的消息队列有 Kafka,主打处理 feed;RabbitMQ、ActiveMQ、 RocketMQ 等主打分布式应用间通信(应用解耦)。