环境信息
使用的 hadoop 完全分布式集群
1 | 192.168.2.241 hadoop01 |
filebeat 安装
使用 flink on yarn
官网 https://flink.apache.org/downloads.html
https://flink.apache.org/downloads.html#flink-shaded
hadoop011
2
3
4
5
6
7
8wget --no-check-certificate https://dlcdn.apache.org/flink/flink-1.15.0/flink-1.15.0-bin-scala_2.12.tgz
mkdir -p /opt/bigdata/flink
tar -zxf flink-1.15.0-bin-scala_2.12.tgz -C /opt/bigdata/flink
cd /opt/bigdata/flink/
ln -s flink-1.15.0 current
chown -R hadoop:hadoop /opt/bigdata/flink/
兼容需要重新编译,flink-shaded 包含了 Flink 的很多依赖,其中就有 flink-shaded-hadoop-2
最好在服务器外编译,完成后导入1
2
3wget https://archive.apache.org/dist/flink/flink-shaded-15.0/flink-shaded-15.0-src.tgz
tar -zxf flink-shaded-15.0-src.tgz
cd flink-shaded-15.0
拷贝 flink-shaded-9.0/flink-shaded-hadoop-2-uber/target/flink-shaded-hadoop-2-uber-3.3.2-9.0.jar 到服务器 /opt/bigdata/flink/current/lib/
测试 flink on yarn
在 Flink on Yarn 模式下,提交 Flink 任务到 Yarn,分为两种模式
- Session-Cluster
- Per-Job-Cluster 模式
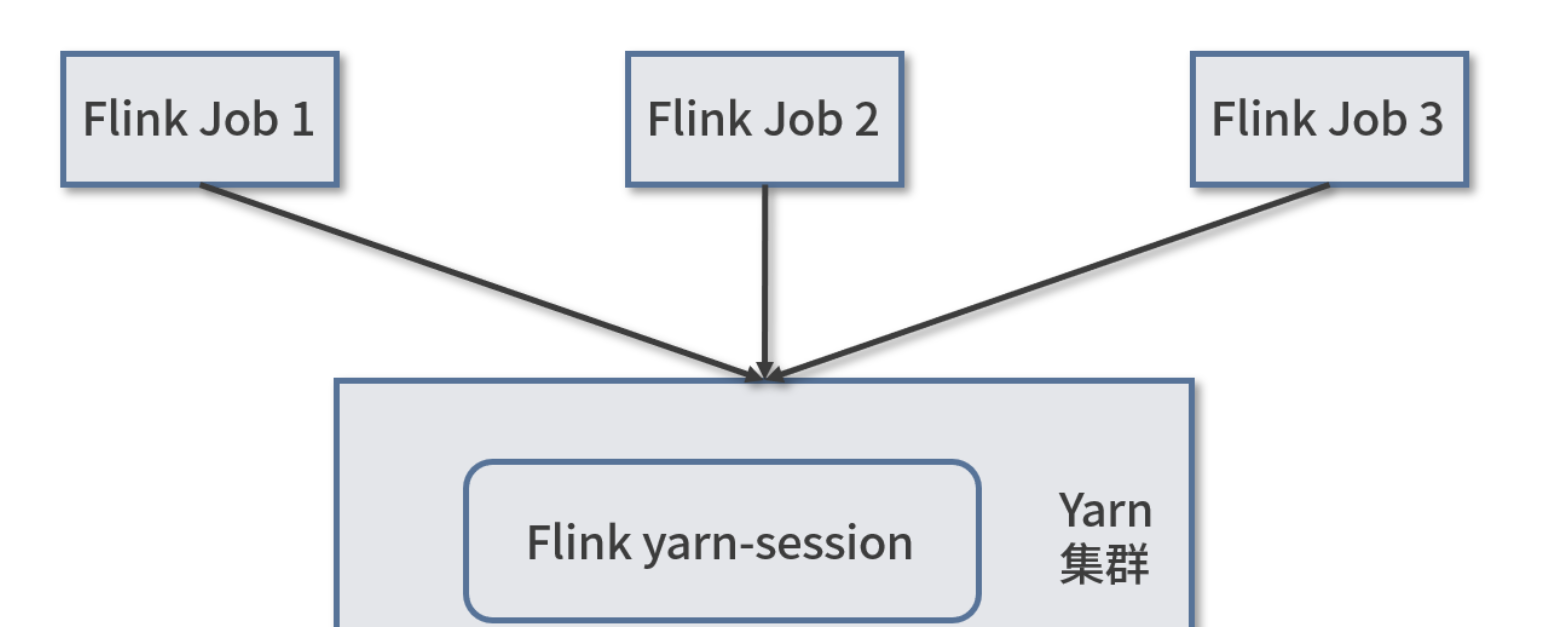
Session-Cluster 模式 : 需要提前在 Yarn 中初始化一个 Flink 集群,并申请指定的集群资源池,以后的 Flink 任务都会提交到这个资源池下运行。该 Flink 集群会常驻在 Yarn 集群中,除非手工停止
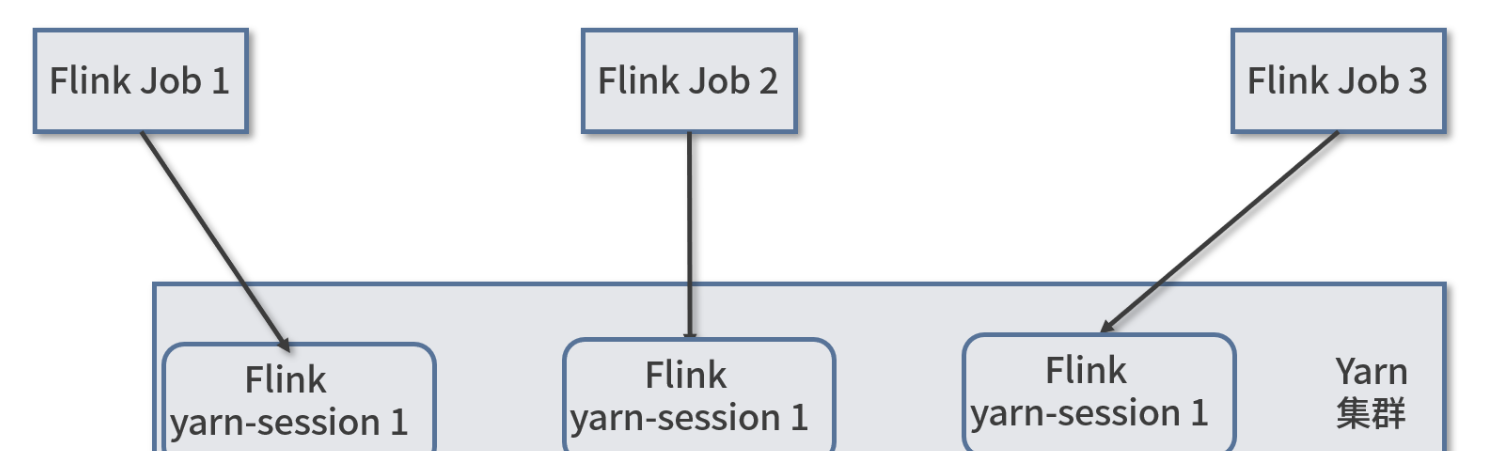
Per-Job-Cluster 模式 : 每次提交 Flink 任务,都会创建一个新的 Flink 集群,每个 Flink 任务之间相互独立、互不影响。任务执行完成之后创建的 Flink 集群资源也会随之释放,不会额外占用资源,这种按需使用模式,可以使集群资源利用率达到最大
Session-Cluster 模式
1 | $ cd /opt/bigdata/flink/current/ |
可以看到 Web Interface http://hadoop01:33237, 以及关闭job方法
测试 (/demo/demo.txt 之前有多次上传,参考前文)1
2
3
4
5
6
7
8
9
10./bin/flink run /opt/bigdata/flink/current/examples/batch/WordCount.jar --input hdfs://bigdata/demo/demo.txt --output hdfs://bigdata/logs/count
$ hdfs dfs -text /logs/count
hadoop 4
hive 2
linux 3
mapreduce 1
spark 2
unix 2
windows 2
Pre-Job-Cluster 模式
需要先关闭 Session-Cluster1
echo "stop" | ./bin/yarn-session.sh -id application_1652942203850_0022
测试1
2
3
4
5
6
7
8
9
10
11
12$ hdfs dfs -rm /logs/count
$ ./bin/flink run -m yarn-cluster -ys 4 -yjm 2048 -ytm 3072 /opt/bigdata/flink/current/examples/batch/WordCount.jar --input hdfs://bigdata/demo/demo.txt --output hdfs://bigdata/logs/count
$ hdfs dfs -text /logs/count
hadoop 4
hive 2
linux 3
mapreduce 1
spark 2
unix 2
windows 2
能看到结果
网页查看
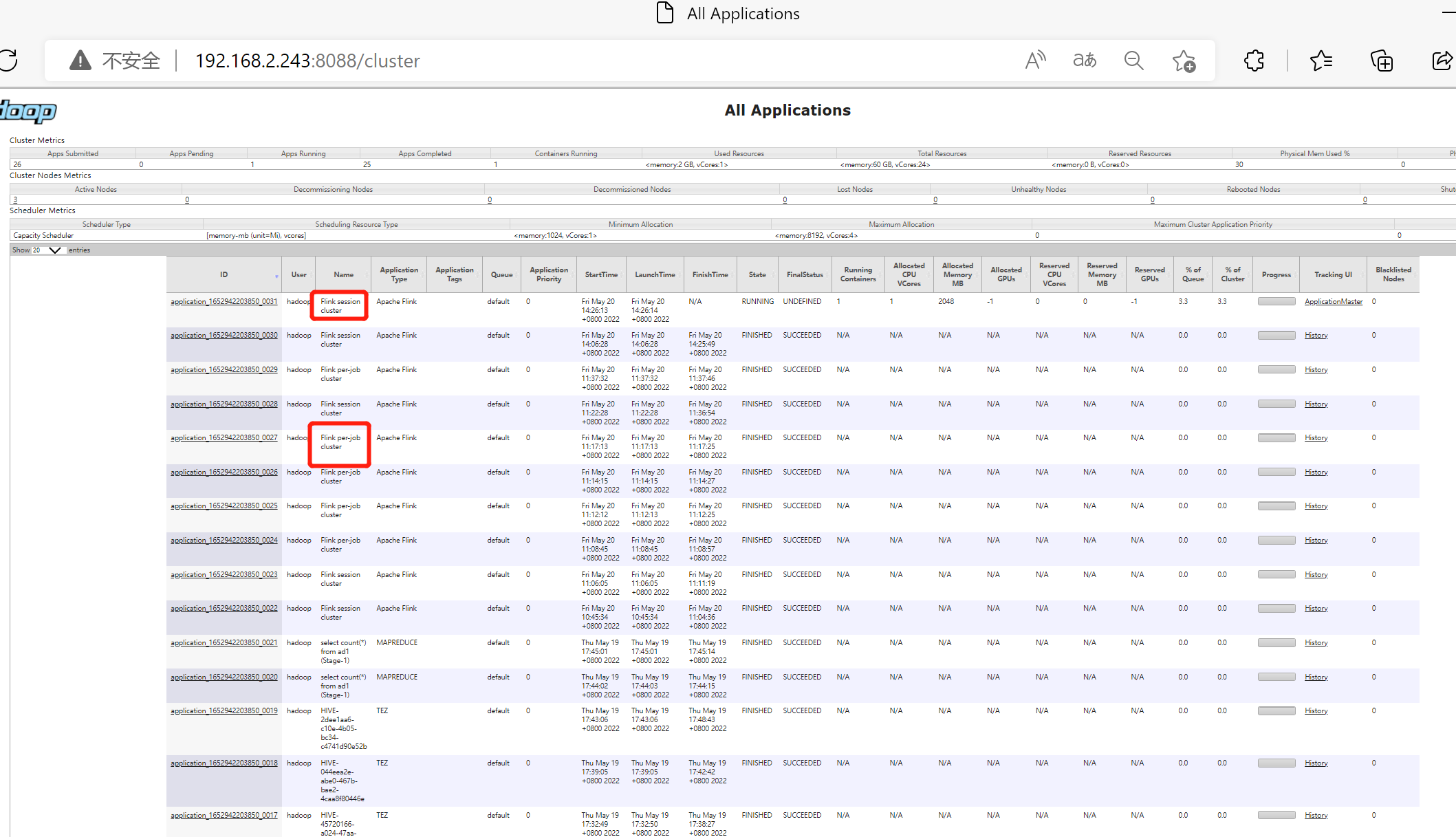
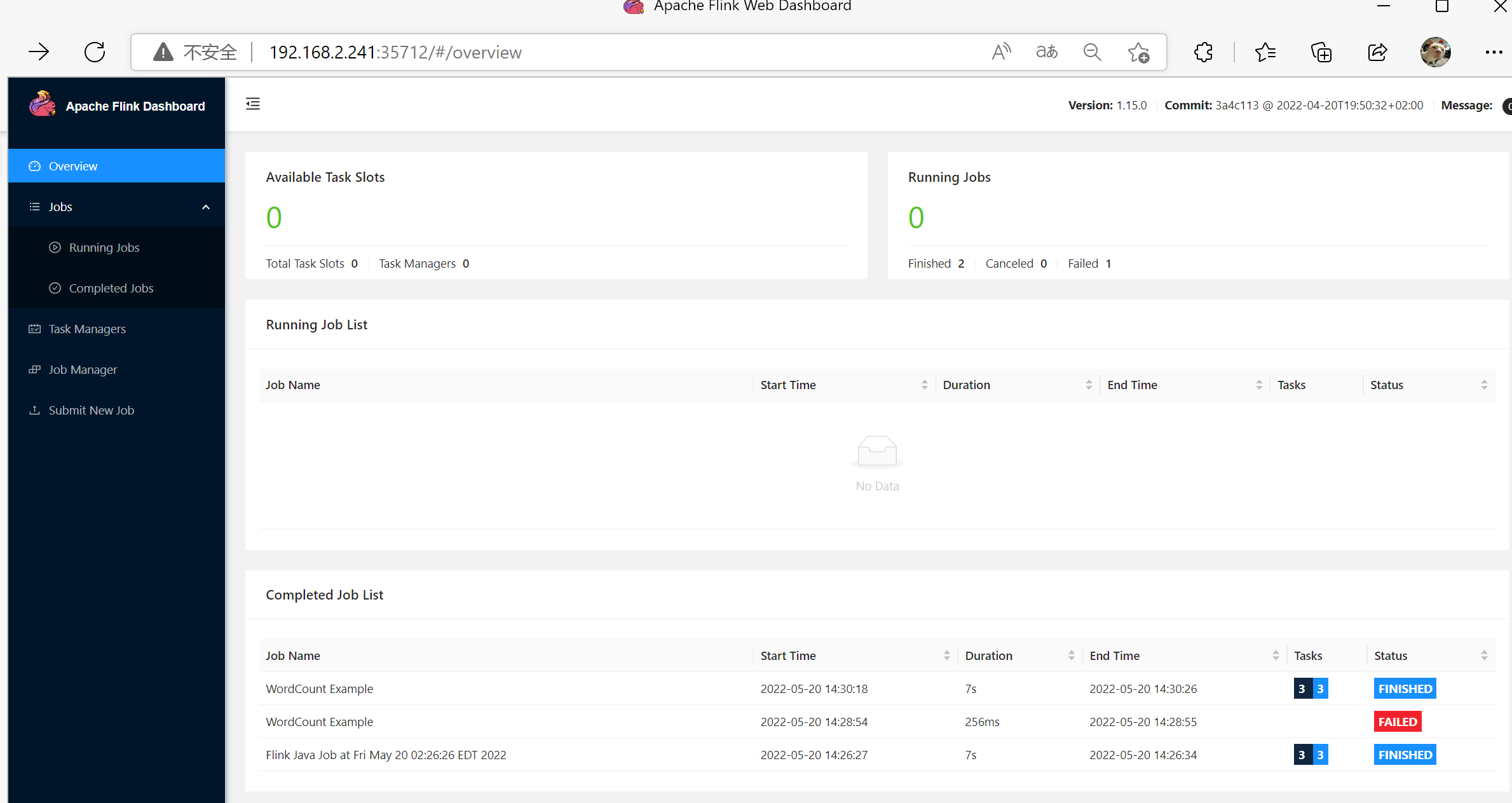
遇到的问题
- classloader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.ensureInner(FlinkUserCodeClassLoaders.java:164)
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.getResource(FlinkUserCodeClassLoaders.java:183)
at org.apache.hadoop.conf.Configuration.getResource(Configuration.java:2830)
at org.apache.hadoop.conf.Configuration.getStreamReader(Configuration.java:3104)
at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3063)
at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:3036)
at org.apache.hadoop.conf.Configuration.loadProps(Configuration.java:2914)
at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2896)
at org.apache.hadoop.conf.Configuration.get(Configuration.java:1246)
at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1863)
at org.apache.hadoop.conf.Configuration.getTimeDuration(Configuration.java:1840)
at org.apache.hadoop.util.ShutdownHookManager.getShutdownTimeout(ShutdownHookManager.java:183)
at org.apache.hadoop.util.ShutdownHookManager.shutdownExecutor(ShutdownHookManager.java:145)
at org.apache.hadoop.util.ShutdownHookManager.access$300(ShutdownHookManager.java:65)
at org.apache.hadoop.util.ShutdownHookManager$1.run(ShutdownHookManager.java:102)
修改 /opt/bigdata/flink/current/conf/flink-conf.yaml,
添加 classloader.check-leaked-classloader: false
大致位置1
2# classloader.resolve-order: child-first
classloader.check-leaked-classloader: false
测试可以正常运行
- 资源限制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: java.util.concurrent.ExecutionExce: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:836)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:247)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1078)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1156)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1878)
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1156)
Caused by: java.lang.RuntimeException: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.ru.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:319)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1061)
at org.apache.flink.client.program.ContextEnvironment.executeAsync(ContextEnvironment.java:132)
at org.apache.flink.client.program.ContextEnvironment.execute(ContextEnvironment.java:70)
at org.apache.flink.examples.java.wordcount.WordCount.main(WordCount.java:93)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355)
... 11 more
Caused by: java.util.concurrent.ExecutionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializatieption: Could not start the JobMaster.
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1056)
... 19 more
Caused by: java.lang.RuntimeException: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaste
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:319)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedFunction$2(FunctionUtils.java:75)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
at java.util.concurrent.CompletableFuture$Completion.exec(CompletableFuture.java:457)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1067)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1703)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:172)
Caused by: org.apache.flink.runtime.client.JobInitializationException: Could not start the JobMaster.
at org.apache.flink.runtime.jobmaster.DefaultJobMasterServiceProcess.lambda$new$0(DefaultJobMasterServiceProcess.java:9
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1609)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.util.concurrent.CompletionException: java.lang.RuntimeException: org.apache.flink.runtime.client.JobExecutionExon: Cannot initialize task 'DataSink (CsvOutputFormat (path: hdfs://bigdata/logs/count, delimiter: ))': File or directory alrexists. Existing files and directories are not overwritten in NO_OVERWRITE mode. Use OVERWRITE mode to overwrite existing files irectories.
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1606)
... 3 more
Caused by: java.lang.RuntimeException: org.apache.flink.runtime.client.JobExecutionException: Cannot initialize task 'DataSink utputFormat (path: hdfs://bigdata/logs/count, delimiter: ))': File or directory already exists. Existing files and directoriesnot overwritten in NO_OVERWRITE mode. Use OVERWRITE mode to overwrite existing files and directories.
at org.apache.flink.util.ExceptionUtils.rethrow(ExceptionUtils.java:319)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedSupplier$4(FunctionUtils.java:114)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604)
... 3 more
Caused by: org.apache.flink.runtime.client.JobExecutionException: Cannot initialize task 'DataSink (CsvOutputFormat (path: hdfsgdata/logs/count, delimiter: ))': File or directory already exists. Existing files and directories are not overwritten in NO_OITE mode. Use OVERWRITE mode to overwrite existing files and directories.
at org.apache.flink.runtime.executiongraph.DefaultExecutionGraphBuilder.buildGraph(DefaultExecutionGraphBuilder.java:17
at org.apache.flink.runtime.scheduler.DefaultExecutionGraphFactory.createAndRestoreExecutionGraph(DefaultExecutionGraphry.java:149)
at org.apache.flink.runtime.scheduler.SchedulerBase.createAndRestoreExecutionGraph(SchedulerBase.java:363)
at org.apache.flink.runtime.scheduler.SchedulerBase.<init>(SchedulerBase.java:208)
at org.apache.flink.runtime.scheduler.DefaultScheduler.<init>(DefaultScheduler.java:191)
at org.apache.flink.runtime.scheduler.DefaultScheduler.<init>(DefaultScheduler.java:139)
at org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:135)
at org.apache.flink.runtime.jobmaster.DefaultSlotPoolServiceSchedulerFactory.createScheduler(DefaultSlotPoolServiceScheFactory.java:115)
at org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:345)
at org.apache.flink.runtime.jobmaster.JobMaster.<init>(JobMaster.java:322)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.internalCreateJobMasterService(DefaultJoerServiceFactory.java:106)
at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.lambda$createJobMasterService$0(DefaultJterServiceFactory.java:94)
at org.apache.flink.util.function.FunctionUtils.lambda$uncheckedSupplier$4(FunctionUtils.java:112)
... 4 more
Caused by: java.io.IOException: File or directory already exists. Existing files and directories are not overwritten in NO_OVER mode. Use OVERWRITE mode to overwrite existing files and directories.
at org.apache.flink.core.fs.FileSystem.initOutPathDistFS(FileSystem.java:995)
at org.apache.flink.api.common.io.FileOutputFormat.initializeGlobal(FileOutputFormat.java:299)
at org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.initializeOnMaster(InputOutputFormatVertex.java:110)
at org.apache.flink.runtime.executiongraph.DefaultExecutionGraphBuilder.buildGraph(DefaultExecutionGraphBuilder.java:17
... 16 more
yarn 和 flink 资源都有限制,需要充分考虑修改,不然可能导致资源不足任务失败。当前改为比较小的资源测试
/opt/bigdata/flink/current/conf/flink-conf.yaml 部分配置
1 | jobmanager.memory.process.size: 1600m |