本地运行模式
详细参考 hadoop 部署一章
验证
创建文件
1
2
3
4
5
6
7
8
9
10
11su - hadoop
cd /opt/bigdata/hadoop/current
mkdir wcinput
cat > /opt/bigdata/hadoop/current/wcinput/demo.txt <<-EOF
Linux Unix windows
hadoop Linux spark
hive hadoop Unix
MapReduce hadoop Linux hive
windows hadoop spark
EOF执行程序
1
2cd /opt/bigdata/hadoop/current
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount wcinput wcoutput查看结果
1 | # ls wcoutput/ |
备注1
2
3_SUCCESS : 任务完成标识,表示执行成功;
part-r-00000 : m 标识的文件是 mapper 输出,带 r 标识的文件是 reduce 输出的,00000 为 job 任务编号,part-r-00000 整个文件为结果输出文件
单节点伪分布式示例
基本和完全分布式部署差不多,主要是配置文件有差异。先测试单节点伪分布式
节点 192.168.2.231,前置操作已经操作完。hosts 文件, 使用默认配置,仅作部分修改
192.168.2.231 hadoop231
/etc/hadoop/conf/core-site.xml, 改为当前节点,默认端口 rpc 8020
1 | <property> |
日志文件在 /opt/bigdata/hadoop/current/logs/ ,遇到问题可以看日志定位
启动 NameNode 服务
格式化
NameNode1
2
3$ su - hadoop
$ cd /opt/bigdata/hadoop/current/bin
$ hdfs namenode -format启动
NameNode
1 | $ hdfs --daemon start namenode |
- 验证
1
2$ jps|grep NameNode
27319 NameNode
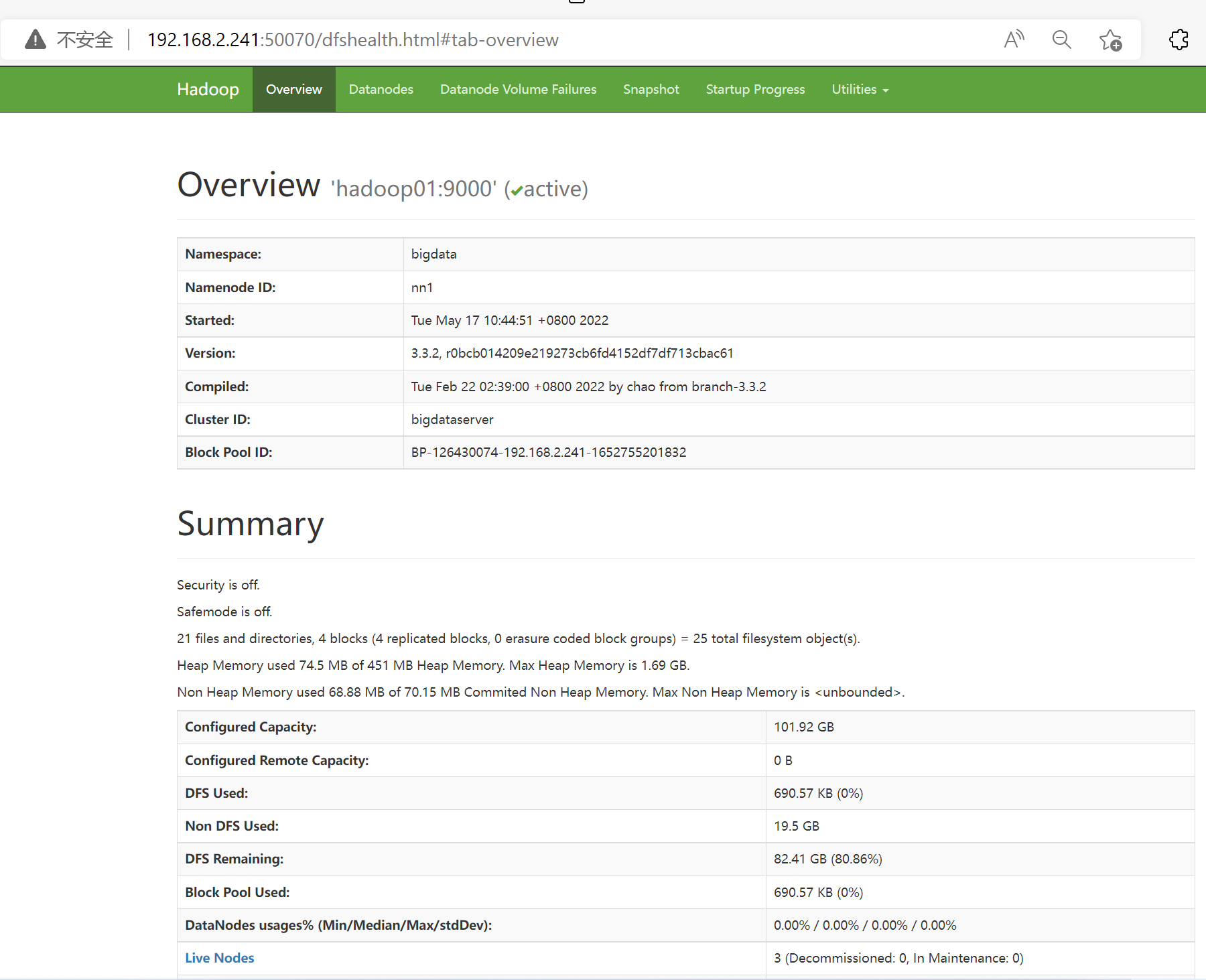
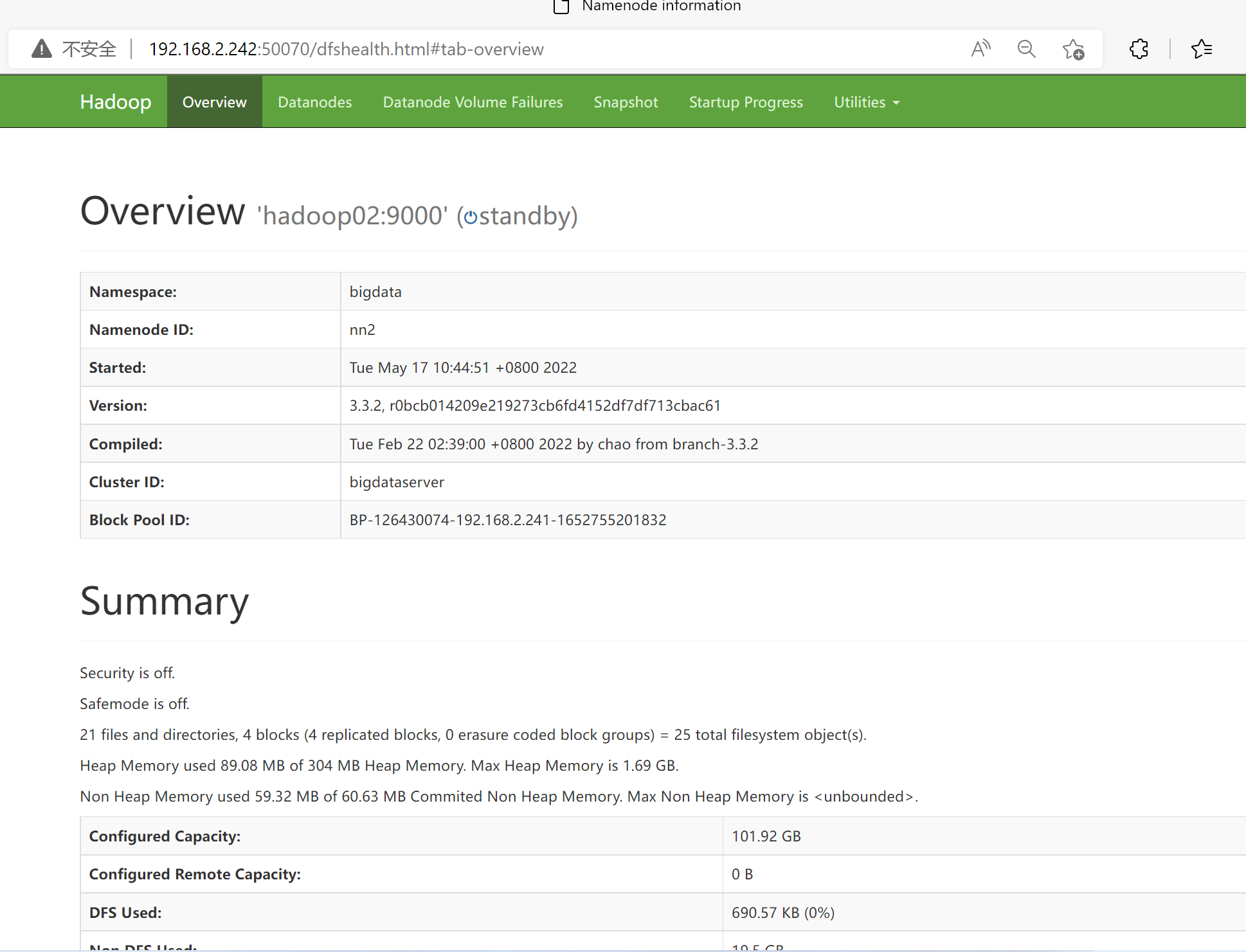
192.168.2.231:9870
NameNode 服务状态页面
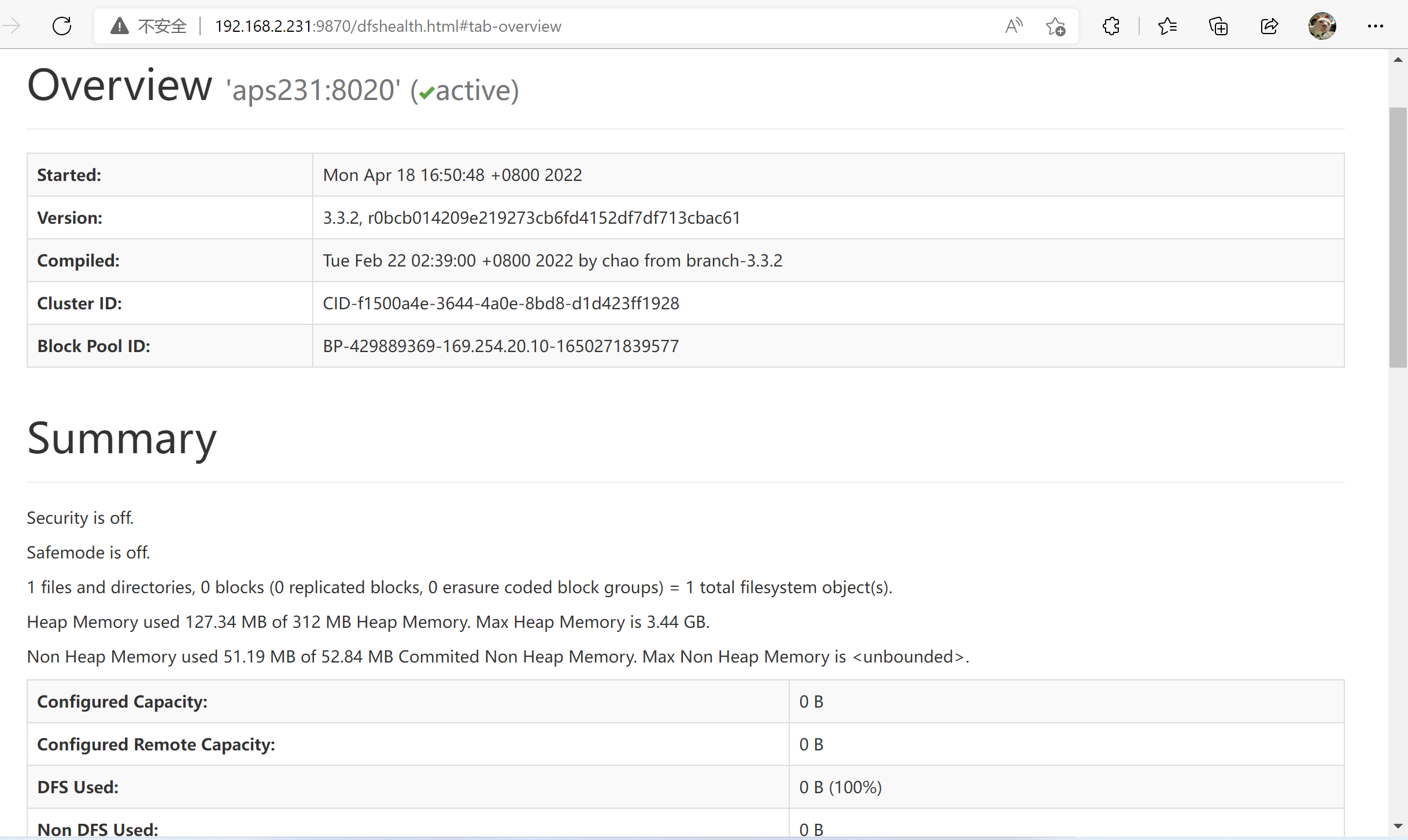
datanode 还没有启动等,无数据
- 启动
secondarynamenode(分布式可以不需要这个服务)1
2
3$ hdfs --daemon start secondarynamenode
$ jps|grep SecondaryNameNode
29705 SecondaryNameNode
启动 DataNode 服务
- 启动
DataNode
1 | hdfs --daemon start datanode |
- 验证
1
2$ jps|grep DataNode
3876 DataNode
192.168.2.231:9870
NameNode 服务状态页面
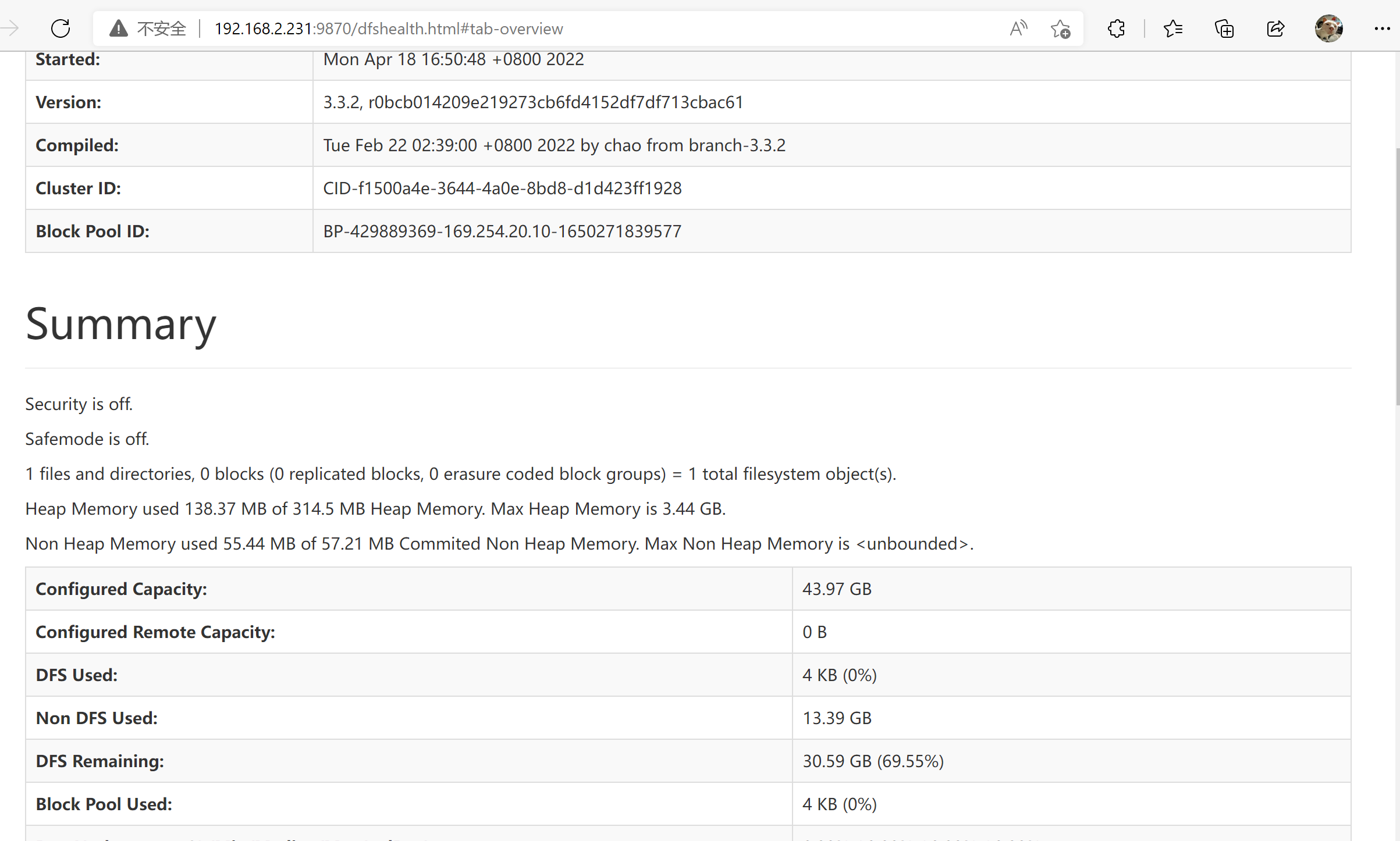
可以看到已有活动的节点等
启动 ResourceManager 服务
- 启动
ResourceManager
1 | $ yarn --daemon start resourcemanager |
- 验证
1
2$ jps|grep ResourceManager
4726 ResourceManager
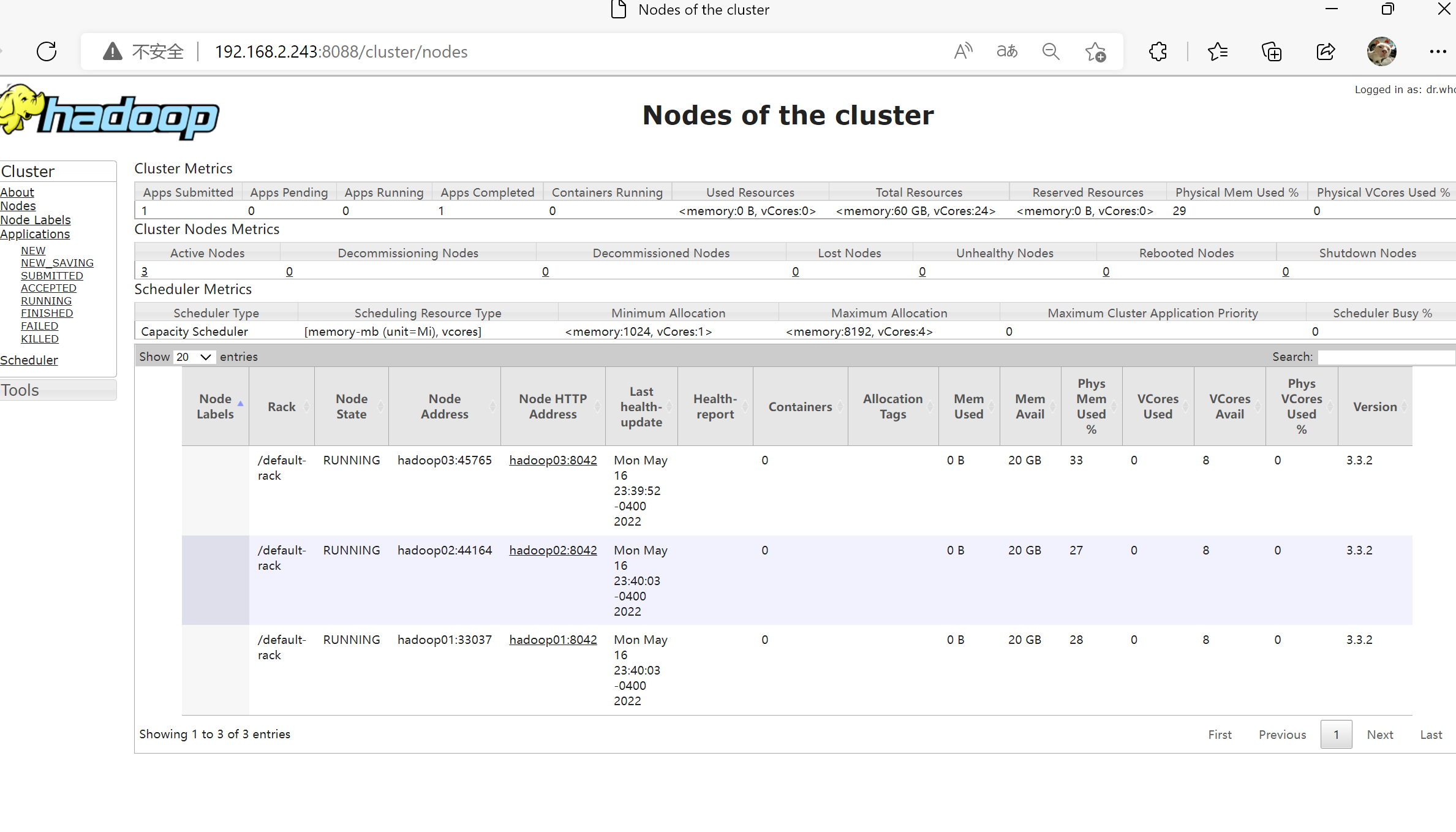
192.168.2.231:8088
ResourceManager 的状态页面
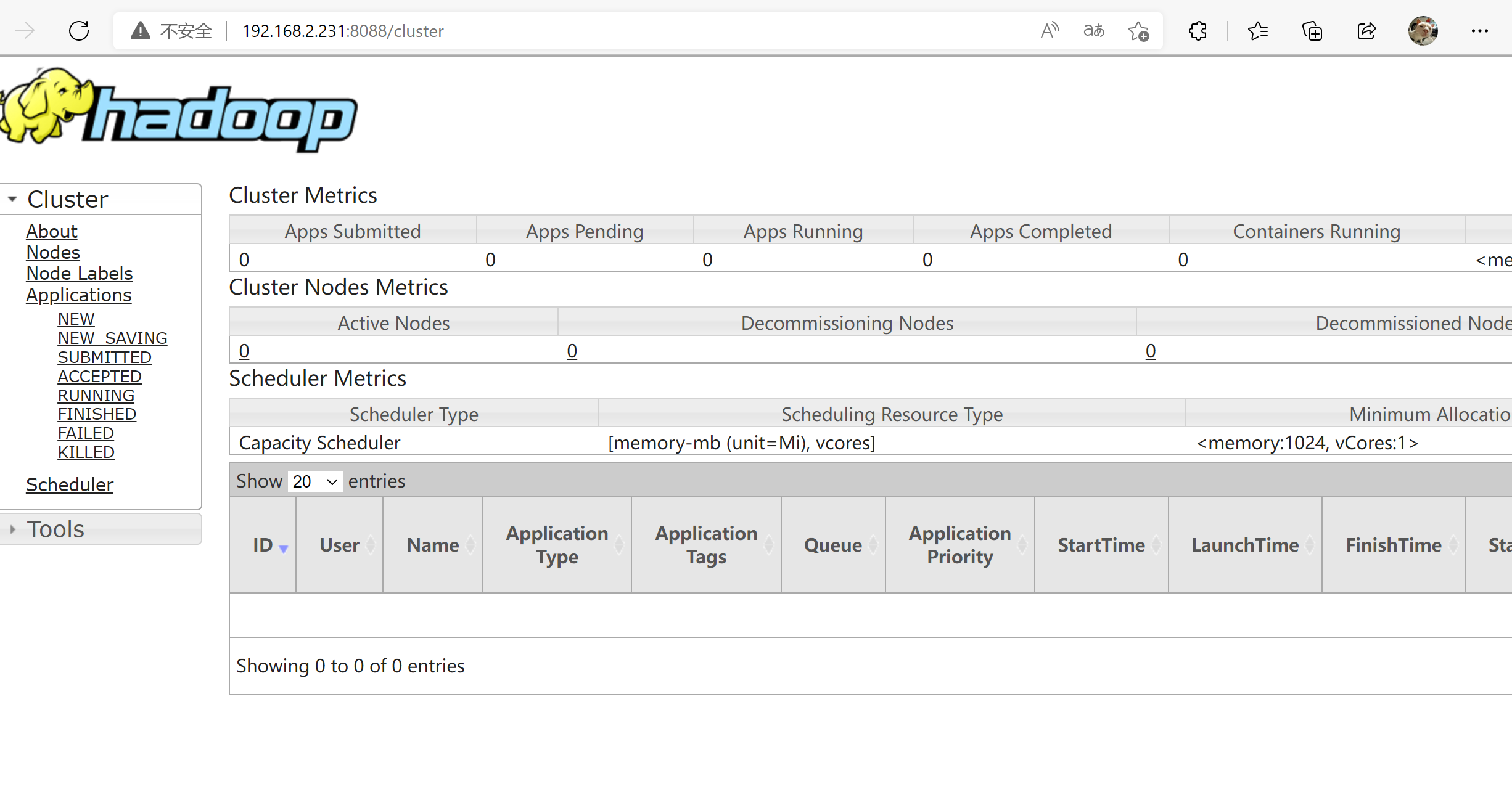
ResourceManager 中可用的内存资源、CPU 资源数及活跃节点数这些数据都是 0,是因为还没有 NodeManager 服务启动。
启动 NodeManager 服务
启动
ResourceManager1
$ yarn --daemon start nodemanager
验证
1 | $ jps|grep NodeManager |
ResourceManager 的状态页面
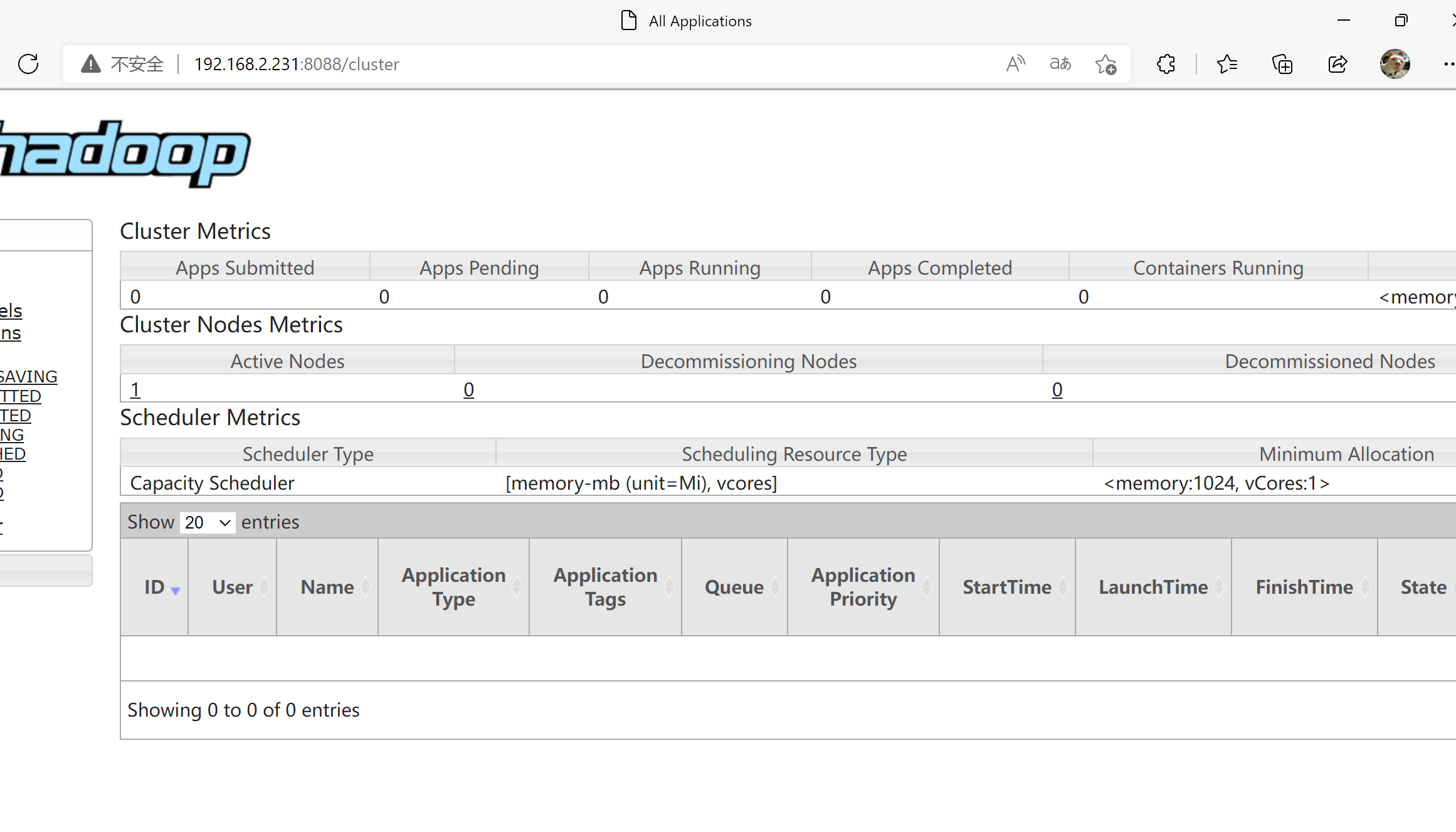
启动 Jobhistoryserver 服务
启动
Jobhistoryserver1
$ mapred --daemon start historyserver
验证
1
2$ jps|grep JobHistoryServer
1027 JobHistoryServer
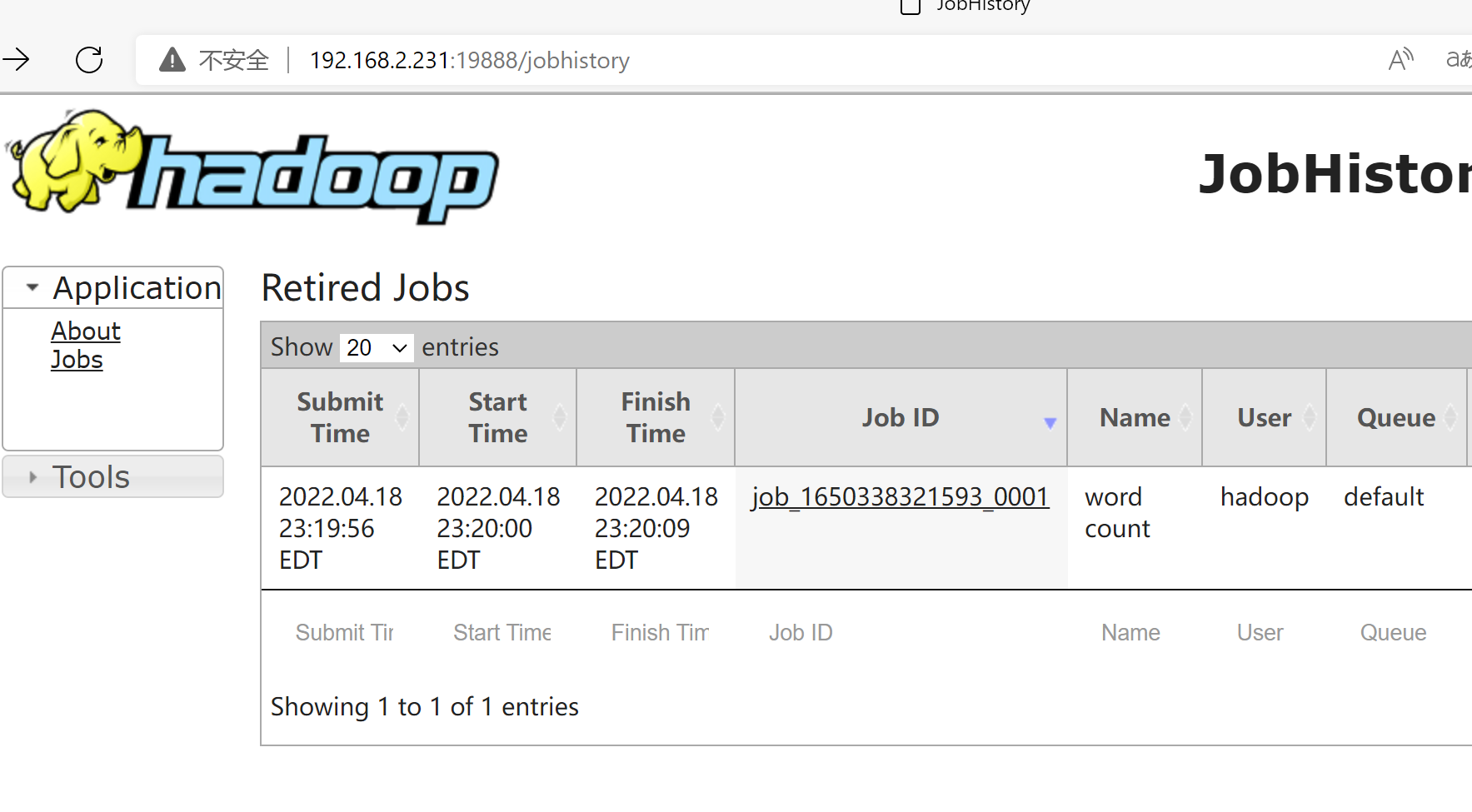
192.168.2.231:19888 JobHistoryServer
以上设置为最简配置
默认 mapreduce 的运行环境是 local(本地),要让 mapreduce 在 yarn 上运行, 需要修改
- 修改文件
mapred-site.xml:
1 | <configuration> |
yarn-site.xml :
1 | <property> |
- 重启服务 ResourceManager 与 nodemanager
1 | yarn --daemon stop resourcemanager |
测试
1 | cat > /tmp/demo.txt <<-EOF |
结果1
2
3
4
5
6
7
8$ hadoop fs -text /output/part-r-00000
Linux 3
MapReduce 1
Unix 2
hadoop 4
hive 2
spark 2
windows 2
遇到的问题
namenode 与 datanode 冲突
服务器重启后,重新 hdfs namenode -format 导致 version 不一致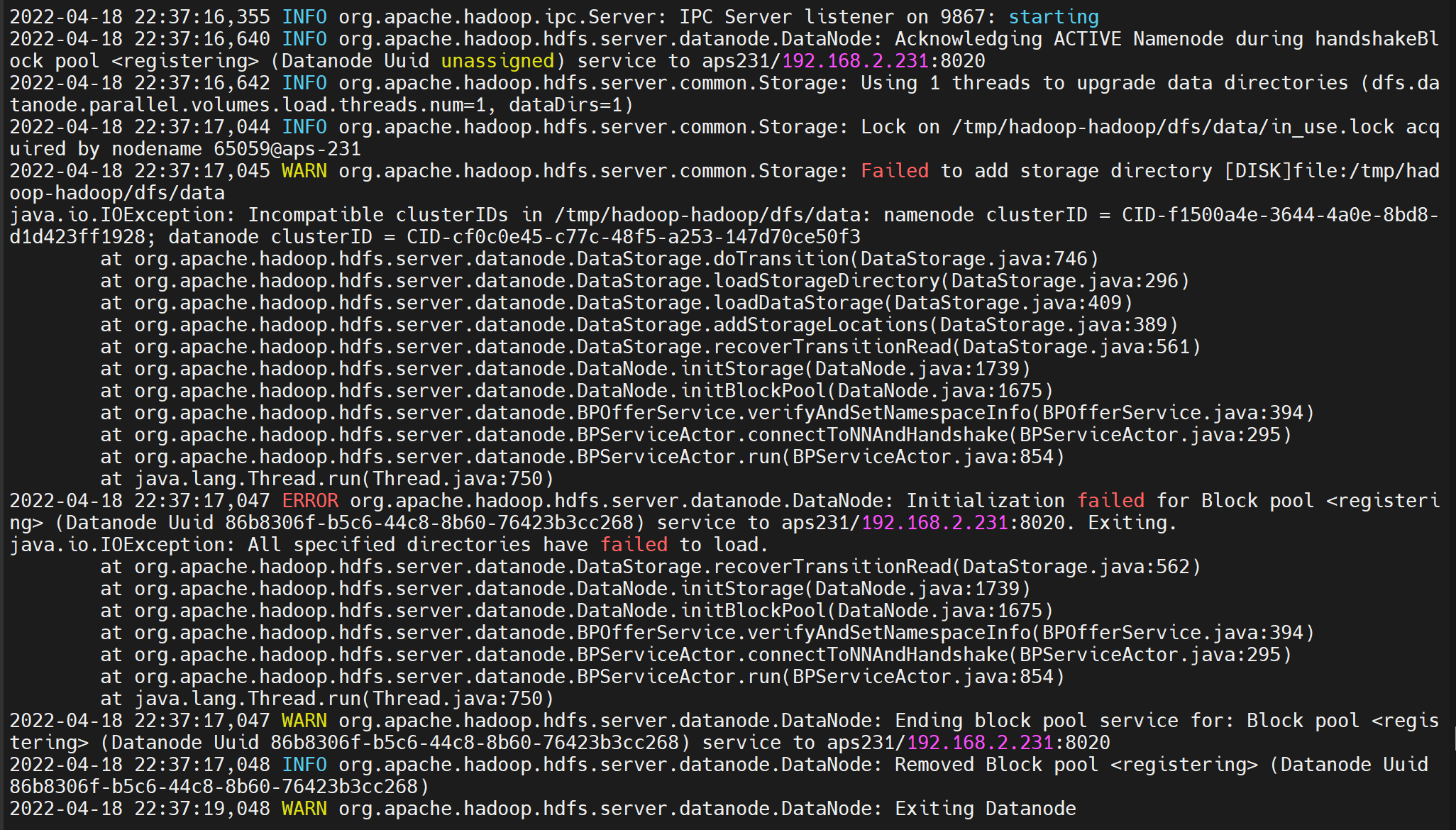
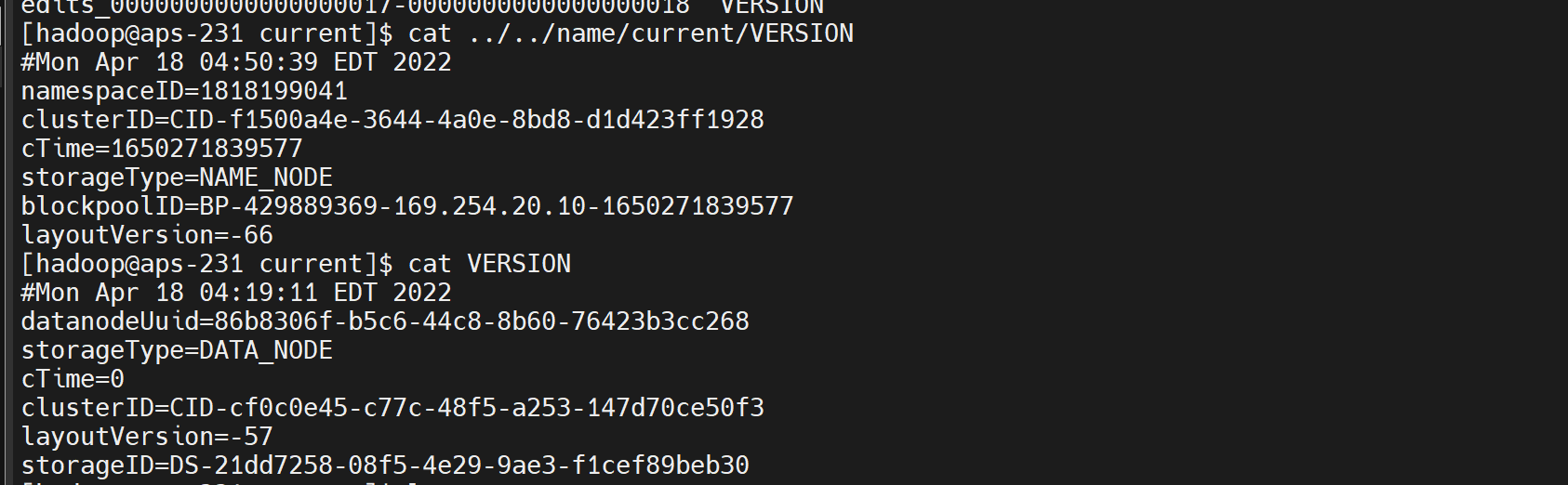
备份后 删除 data tmp 文件
mapreduce 改为集群后, yarn-site 当时未修改
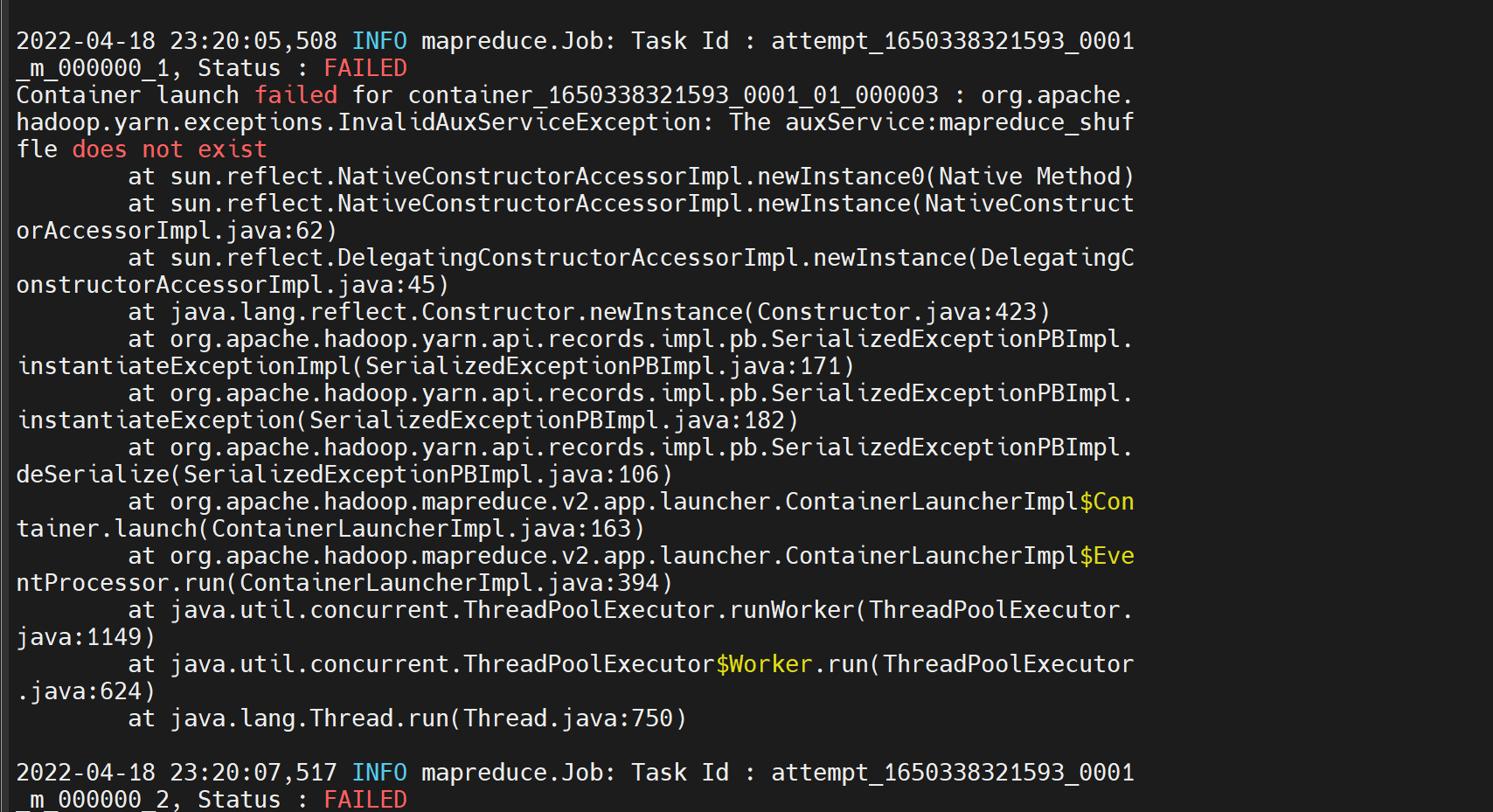
改完后,重启重跑任务正常
完全分布式运行模式
前置操作
所有节点均先完成 前置操作,hadoop 原生安装 (本地运行模式) 的操作。详细参考 hadoop 部署
当前 /etc/hosts1
2
3
4
5
6
7
8cat >/etc/hosts<<eof
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.241 hadoop01
192.168.2.242 hadoop02
192.168.2.243 hadoop03
eof
节点规划
一般情况下:
- NameNode 服务要独立部署
- datanode 和 nodemanager 服务建议部署在一台服务器上
- resourcemanager 服务要独立部署
- historyserver 一般和 resourcemanager 部署在一起
- ZooKeeper (QuorumPeerMain) 和 JournalNode 集群可以放在一起
- zkfc (DFSZKFailoverController) 是对 NameNode 进行资源仲裁的,所以它必须和 NameNode 服务运行在一起
当前资源限制, 只有三台节点,做如下规划
hadoop01 : QuorumPeerMain, JournalNode, NameNode, DFSZKFailoverController, DataNode, NodeManager
hdaoop02 : QuorumPeerMain, JournalNode, NameNode, DFSZKFailoverController, DataNode, NodeManager
hadoop03 : QuorumPeerMain, JournalNode, DataNode, ResourceManager, NodeManager, JobHistoryServer
安装 zookeeper
官方网站 https://zookeeper.apache.org/releases.html#download
所有节点执行1
2
3
4
5
6wget --no-check-certificate https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
mkdir -p /opt/bigdata/zookeeper
tar -zxvf apache-zookeeper-*-bin.tar.gz -C /opt/bigdata/zookeeper
cd /opt/bigdata/zookeeper
ln -s apache-zookeeper-*-bin current
所有节点执行 修改配置文件及创建文件夹
/opt/bigdata/zookeeper/current/conf/zoo.cfg1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16cat > /opt/bigdata/zookeeper/current/conf/zoo.cfg <<-EOF
tickTime=2000
initLimit=20
syncLimit=10
dataDir=/opt/bigdata/zookeeper/current/data
dataLogDir=/opt/bigdata/zookeeper/current/dataLogDir
clientPort=2181
quorumListenOnAllIPs=true
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
admin.serverPort=8081
EOF
mkdir -p /opt/bigdata/zookeeper/current/data
mkdir -p /opt/bigdata/zookeeper/current/dataLogDir
- 2181 : 对
client端提供服务 - 2888 : 集群内机器通信使用
- 3888 : 选举
leader使用
写入 myid ,每个节点不同
1 | echo 1 > /opt/bigdata/zookeeper/current/data/myid # hdp01 |
所有节点执行授权1
chown -R hadoop:hadoop /opt/bigdata/zookeeper
启动 zookeeper
1 | $ cd /opt/bigdata/zookeeper/current/bin |
日志文件目录 /opt/bigdata/zookeeper/current/logs
修改配置文件及相关操作
配置文件路径 /etc/hadoop/conf ,所有节点均修改
修改配置文件
core-site.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/tmp/hadoop-${user.name}</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>60</value>
</property>
</configuration>hdfs-site.yml
1 | <configuration> |
- mapred-site.xml
1 | <configuration> |
- yarn-site.xml
1 | <configuration> |
- hosts 文件
1 | cat >/etc/hadoop/conf/hosts<<-EOF |
其他操作
根据配置文件创建目录, 所有节点
1 | mkdir -p /data1/hadoop |
安装
均在 hadoop 用户下执行 su hadoop
- 启动与格式化 ZooKeeper 集群 (所有节点)
1 | $ cd /opt/bigdata/zookeeper/current/bin |
- ZooKeeper 格式化 (hadoop01)
1 | hdfs zkfc -formatZK |
启动 JournalNode 集群 (所有节点),产生 /data1/hadoop/dfs/jn
1
2
3$ hdfs --daemon start journalnode
$ jps
15187 JournalNode格式化并启动主节点 NameNode 服务 (hadoop01)
1 | $ hdfs namenode -format -clusterId bigdataserver # 此名称可随便指定 |
- NameNode 主、备节点同步元数据,并启动备节点 (hadoop02)
1 | $ hdfs namenode -bootstrapStandby |
启动 ZooKeeper FailoverController(zkfc)服务 (hadoop01启动后,再启动 hadoop02)
1
2
3$ hdfs --daemon start zkfc
$ jps
1888 DFSZKFailoverController启动存储节点 DataNode 服务 (所有节点)
1 | $ hdfs --daemon start datanode |
- 启动 ResourceManager、NodeManager 及 historyserver 服务
1 | $ yarn --daemon start resourcemanager # hadoop03 |
验证
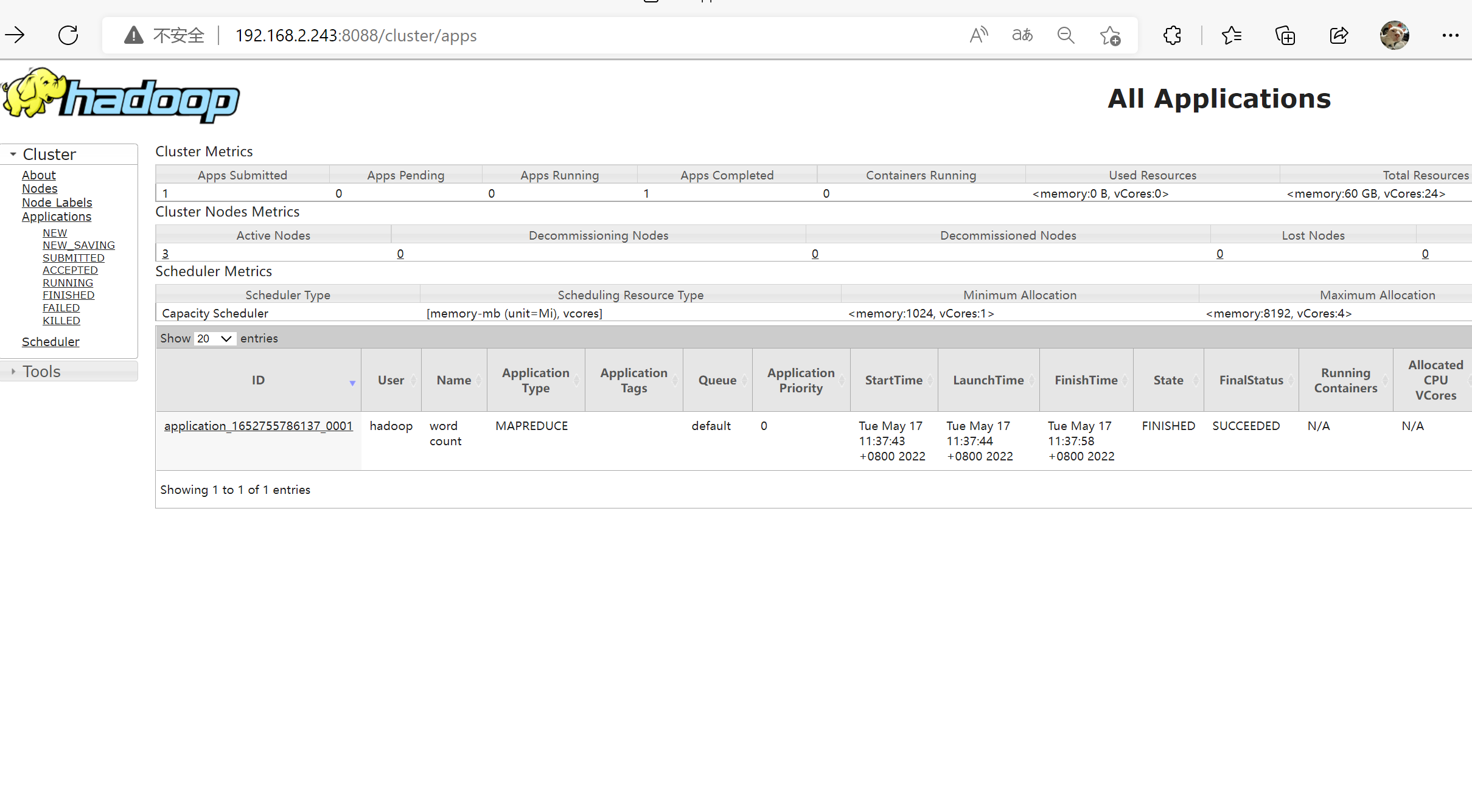
上传文件及 mapreduce1
2
3
4
5
6
7
8
9
10
11
12
13cat > /tmp/demo.txt <<-EOF
Linux Unix windows
hadoop Linux spark
hive hadoop Unix
MapReduce hadoop Linux hive
windows hadoop spark
EOF
hadoop fs -mkdir /demo
hadoop fs -put /tmp/demo.txt /demo
hadoop jar /opt/bigdata/hadoop/current/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /demo /output
hadoop fs -ls /output
结果1
2
3
4
5
6
7
8$ hadoop fs -text /output/part-r-00000
Linux 3
MapReduce 1
Unix 2
hadoop 4
hive 2
spark 2
windows 2
网页