控制器说明
Pod 分类
主要是生命周期不一致
- 自主式
Pod:Pod退出了,就不会再被创建 - 控制器
Pod: 在控制器的生命周期里,始终要维持Pod的副本数目
命令式编程与声明式编程
- 命令式 : 侧重于如何实现程序,需要把程序的实现过程按照逻辑结果一步一步写下来 (rs) create
- 声明式编程 : 侧重于定义想要什么,然后告诉计算机、引擎,让他帮你去实现 (Deployment) apply
RC 和 RS
ReplicationController (RC) : 用来确保 容器应用的副本数始终保持在用户定义的副本数,如有容器异常退出,会自动创建新的 Pod 来替代,异常多出来的容器也会自动回收
RelicaSet (RS) : 同 RC, 支持集合式的 selector ,(通过 lables 选择),一般只用 RS
Deployment
Deployment : 为 Pod 和 RelicaSet 提供一个声明式定义方法(declarative)
定义 Deployment , Deployment 是通过 RelicaSet 管理 Pod
- 滚动升级回滚应用 :
kubectl apply -f editd_deployment.yaml,kubectl rollout undo deployment nginx-deploy - 扩容和缩容 :
kubectl scale - 重启,暂停和继续 :
kubectl rollout restart, kubectl rollout pause, kubectl rollout resume
eg: 升级 RS 升级到 RS1
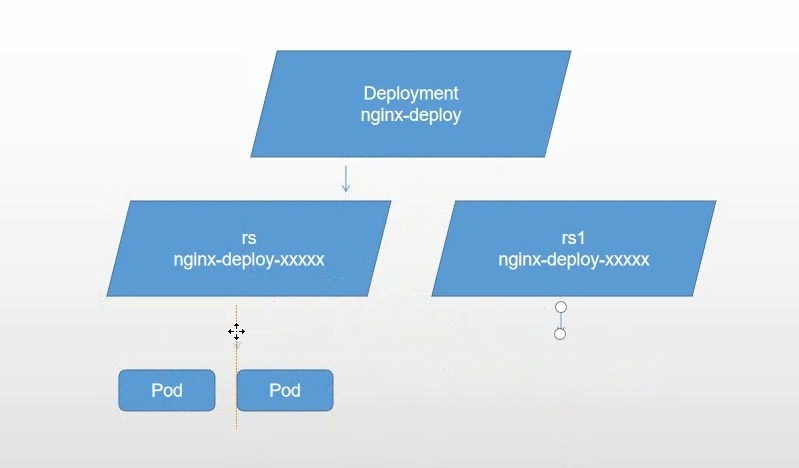
DaemonSet
DaemonSet 确保全部(或者一些( Node 打上污点)(标签选择)) Node 上运行 一个 Pod 副本。
有新 Node 加入集群,会为他们新增一个 Pod, Node 移除 Pod 回收,删除 DaemonSet 会删除它创建的所有 Pod。
DaemonSet 只管理 Pod 对象,然后通过 nodeAffinity 和 Toleration 这两个调度器的小功能,保证了每个节点上有且只有一个 Pod
在 Kubernetes 项目中,当一个节点的网络插件尚未安装时,这个节点就会被自动加上名为 node.kubernetes.io/network-unavailable 的“污点”。
假如当前 DaemonSet 管理的,是一个网络插件的 Agent Pod,那么你就必须在这个 DaemonSet 的 YAML 文件里,给它的 Pod 模板加上一个能够“容忍” node.kubernetes.io/network-unavailable “污点”的 Toleration 。正如下面这个例子所示:
1 | ... |
常用于
- 运行集群存储守护进程—如
glusterd和ceph - 日志收集进程如
fluentd和logstash, - 监控进程—如
Prometheus的NodeExporter、collectd、Datadog agent和Ganglia的gmond等。
Job 和 cronJob
Job :用于管理运行完成后即可终止的应用,例如批处理作业任务;
Job 创建一个或多个 Pod,并确保其符合目标数量,直到 Pod 正常结束而终止。
Job Controller 实际上控制了,作业执行的并行度,以及总共需要完成的任务数这两个重要参数。而在实际使用时,你需要根据作业的特性,来决定并行度(parallelism)和任务数(completions)的合理取值。
cronJob 在特定时间循环创建 Job. CronJob 与 Job 的关系,正如同 Deployment 与 ReplicaSet 的关系一样。CronJob 是一个专门用来管理 Job 对象的控制器。只不过,它创建和删除 Job 的依据,是 schedule 字段定义的、一个标准的 Unix Cron格式的表达式
由于定时任务的特殊性,很可能某个 Job 还没有执行完,另外一个新 Job 就产生了。这时候,你可以通过 spec.concurrencyPolicy 字段来定义具体的处理策略。
concurrencyPolicy: Allow,这也是默认情况,这意味着这些Job可以同时存在;concurrencyPolicy: Forbid,这意味着不会创建新的Pod,该创建周期被跳过;concurrencyPolicy: Replace,这意味着新产生的Job会替换旧的、没有执行完的Job。
startingDeadlineSeconds: 200 在过去的 200秒,如果 miss 的数目达到了 100 次,那么这个 Job 就不会被创建执行了。
job 成功结束后一直处于 completed 状态, 需要手动清除。
StatefulSet
有状态服务
StatefulSet :用于管理有状态的持久化应用,如 database 服务程序;
与 Deployment 的不同之处在于 StatefulSet 会为每个 Pod 创建一个独有的持久性标识符,并会确保各 Pod 之间的顺序性。(部署和scale顺序)
常用场景
- 稳定的持久化存储,
Pod重新调度后还是能访问到相同的持久化数据,基于PVC实现 - 稳定的网络标志,
Pod重新调度后PodName和HostName不变,基于Headless Service实现 (即没有Cluster IP的Service) - 有序部署,有序扩展(0 到 N-1)。
Pod一句定义的顺序依次进行, 基于init containers来实现 - 有序收缩,有序删除 (N-1 到 0)
非级联删除: 删除 sts 后,不删除 pod。此时 pod 则不受控制器管理,删除不恢复--cascade=false
示例1
kubectl delete sts web --cascade=false
补充
金丝雀部署:优先发布一台或少量机器升级,等验证无误后再更新其他机器。优点是用户影响范围小,不足之处是要额外控制如何做自动更新。
蓝绿部署:2组机器,蓝代表当前的V1版本,绿代表已经升级完成的V2版本。通过LB将流量全部导入V2完成升级部署。优点是切换快速,缺点是影响全部用户。
1 | $ kubectl patch statefulset mysql -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":2}}}}' |
比如 MySQL 镜像从 5.7.2 更新到 5.7.23,那么只有序号大于或者等于 2 的 Pod 会被更新到这个版本。并且,如果你删除或者重启了序号小于 2 的 Pod,等它再次启动后,也会保持原先的 5.7.2 版本,绝不会被升级到 5.7.23 版本
Horizontal Pod Autoscaling
使 Pod 水平自动缩放。
不是控制器,可以理解为控制器的附属品.仅适用于 Deployment 和 ReplicaSet.
在 V1 版本中仅支持根据 Pod 的 CPU 利用率扩所容,在 v1alpha 版本中,支持根据内存和用户自定义的 metric 扩缩容
eg:部署 RS 然后用 HPA 管理 RS. CPU >80% 扩容到3个节点 , CPU < 60% 缩容到 2 个节点
1 | kubectl apply -f myapp.yaml |
yaml 文件示例1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: kibana-logging
namespace: logging
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kibana-logging
targetCPUUtilizationPercentage: 50
资源限制
kubernetes 中对容器的限制实际是通过 CGroup 来实现的。
Pod
默认情况下,Pod 运行没有 CPU 和内存的限额。这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样,消耗足够多的 CPU 和内存。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现
在 Kubernetes 中,像 CPU 这样的资源被称作“可压缩资源”( compressible resources )。它的典型特点是,当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。
而像内存这样的资源,则被称作“不可压缩资源( incompressible resources )。当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory) 被内核杀掉。
假设是一个节点4个核心1
2
3
4
5
6
7
8
9
10
11
12
13
14
15spec:
containers:
- image: xxxx
imagePullPolicy: Always
name: auth
ports:
- containerPort: 8080
protocol: TCP
resources:
limits: # 最大值
cpu: "4"
memory: 2Gi
requests: # 初始值
cpu: 250m # 等同于0.25个 即请求 250/4000 的核心
memory: 250M # 1Mi=1024*1024;1M=1000*1000
根据 设置的 Requests 和 limit , kubernetes 支持了三种 QOS 级别。 资源紧张时,会根据分级 决定调度和驱逐策略。
BestEffort: 优先级最低, pod 中没设置Requests和limitBurstable: 中等优先级, 至少定义了Requests,或者Requests和limit不相等。Guaranteed: 高优先级,cpu.limits = cpu.requests,memory.limits = memory.requests。 只定义了limits则requests和limits相等
cpuset 方式,是生产环境里部署在线应用类型的 Pod 时,非常常用的一种方式。这种情况下,由于操作系统在 CPU 之间进行上下文切换的次数大大减少,容器里应用的性能会得到大幅提升
1 | spec: |
ResourceQuota
对 namespace 内资源总量进行限制。
如果分区设置了配额, 那么部署的资源(deployment 或者 statefulset)必须指定配额(request/limit), 包括 init container1
2
3
4
5
6
7
8
9
10
11
12apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: spark-cluster
spec:
hard:
pods: "20"
requests.cpu: "20"
requests.memory: 100Gi
limits.cpu: "40"
limits.memory: 200Gi
对 配置对象数量配额限制1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: spark-cluster
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2
配置CPU和内存 LimitRange
限制 cpu 和 memory 的申请范围,设置默认的申请,限制的值,会在 pod 创建时就注入 Container 中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default: # 即 limit 的值
memory: 512Mi
cpu: 5
defaultRequest: # 即 request 的值
memory: 256Mi
cpu: 1
max:
memory: 1Gi
cpu: 8
min:
memory: 128Mi
cpu: 0.5
maxLimitRequestRatio: # limit/request 的最大比率
memory: 2
cpu: 2
type: Container # Pod PVC 三种类型