BeautifulSoup 解析:基础

具体安装过程可自行搜索。
beautifulSoup使用过程
- 选择要爬的网址 (url)
- 使用 python 打开这个网址 (urlopen等)
- 读取网页信息 (read() 出来)
- 将读取的信息放入 BeautifulSoup
- 使用 BeautifulSoup 选取 tag 信息等 (代替正则表达式)
1
2
3
4
5
6from urllib.request import urlopen
# if has Chinese, apply decode()
html = urlopen(
"https://morvanzhou.github.io/static/scraping/basic-structure.html").read(
).decode('utf-8')
使用BeautifulSoup筛选数据1
2
3
4from bs4 import BeautifulSoup
soup = BeautifulSoup(html, features='lxml') #以 lxml 的这种形式加载
print(soup)
1 | print(soup.h1) # 输出<h1> 标题 |

BeautifulSoup 解析网页:CSS
1 | from bs4 import BeautifulSoup |

BeautifulSoup 解析网页正则表达式
本节代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16html = urlopen(
"https://morvanzhou.github.io/static/scraping/table.html").read(
).decode('utf-8')
print(html)
soup = BeautifulSoup(html, features='lxml')
img_links = soup.find_all("img", {"src": re.compile('.*?\.jpg')})
for link in img_links:
print(link['src'])
print('\n')
course_links = soup.find_all('a', {'href': re.compile('https://morvan.*')})
for link in course_links:
print(link['href'])
我们发现, 如果是图片, 它们都藏在这样一个 tag 中:1
2
3<td>
<img src="https://morvanzhou.github.io/static/img/course_cover/tf.jpg">
</td>
用 soup 将这些 tag 全部找出来, 但是每一个 img 的链接(src)都可能不同,可能是 jpg 有的是 png, 只挑选 jpg 形式的图片, 用这样一个正则 r’.*?.jpg’ 来选取. 把正则的 compile 形式放到 BeautifulSoup 的功能中, 就能选到符合要求的图片链接了.
想要的链接都有统一的形式, 就是开头都会有 https://morvan., 定一个正则, 让 BeautifulSoup 找到符合规则的链接.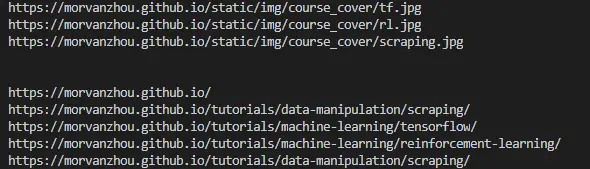
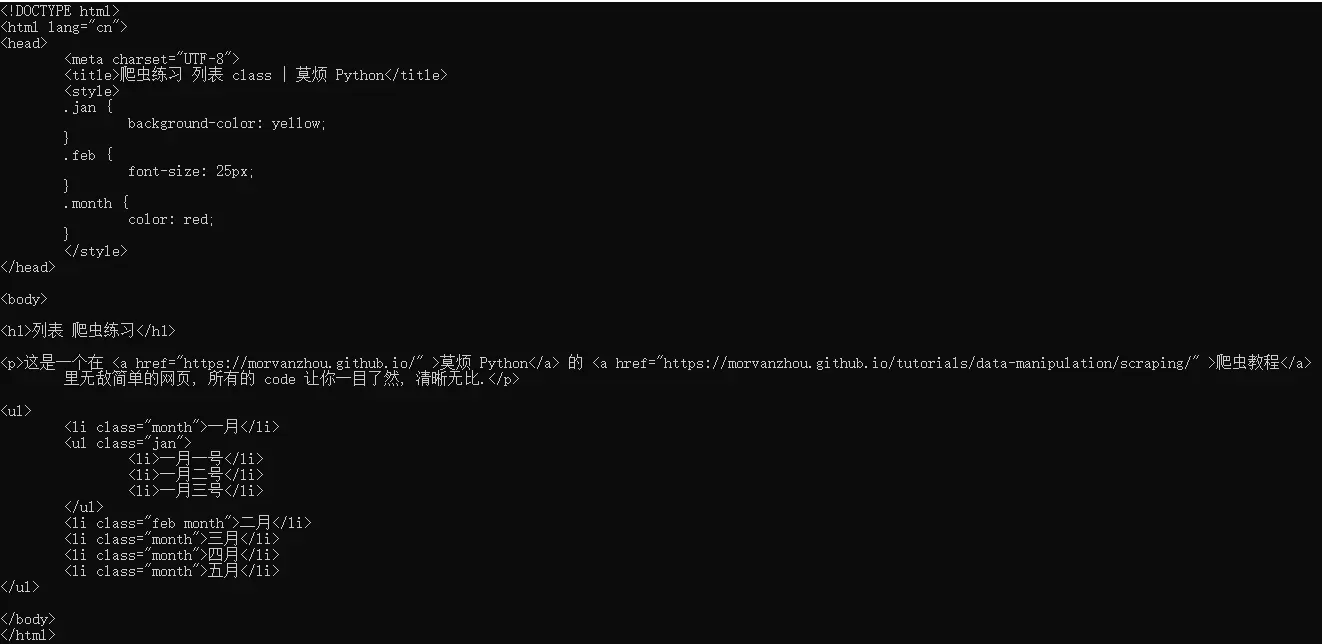
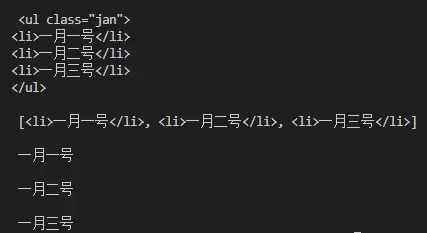
一个小练习来熟悉
1 | from bs4 import BeautifulSoup |