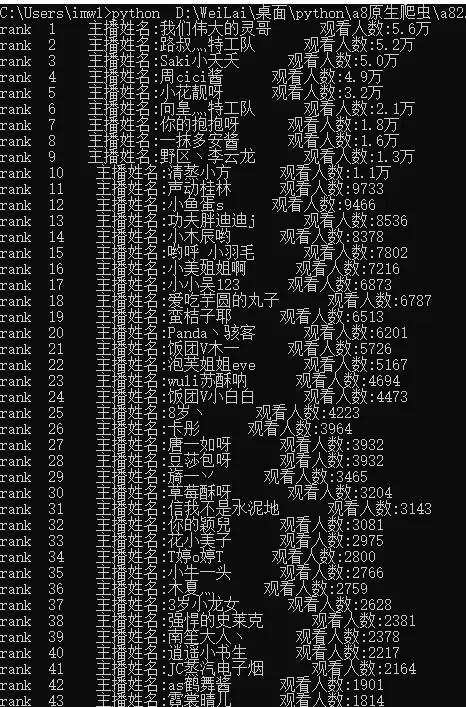
很早前,第一次爬虫,就用的re加urllib原生爬虫。这次重新来爬取一次PandaTV主播人气排名,来练一下手。毕竟看直播嘛,颜值区更喜欢一点。就以颜值区为例,颜值区url = ‘https://www.panda.tv/cate/yzdr'。结果保存在运行目录下的`PandaTV主播人气排名.md`中。
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79import re
from urllib import request
import os
import datetime
class Spider():
url = 'https://www.panda.tv/all'
root_pattern ='<div class="video-info">[\s\S]*?</div>' # 因为number和name均在其下
name_pattern = '<span class="video-nickname" title="([\s\S]*?)">\n'
number_pattern = '<span class="video-number"><i class="ricon ricon-eye"></i>([\s\S]*?)</span>\n'
# 获取htmls数据
def __fetch_content(self):
r = request.Request(Spider.url)
r.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17758')
r = request.urlopen(r) # 打开网页 request 下面的urlopen方法
htmls = r.read() # 读取
htmls = str(htmls, encoding='utf-8') # 转为str
return htmls
# 建立一个list为: [{'name':name,'number': number},{'name':name,'number': number},...]
def __analysis(self, htmls):
root_html = re.findall(Spider.root_pattern, htmls) # 抓取所有的<div class="video-info">[\s\S]*?</div>
anchors = []
for html in root_html: # 将<div class="video-info">[\s\S]*?</div>一个一个提取出来
name = re.findall(Spider.name_pattern, html) # 将一个的name提取出来 ,格式为[str]
number = re.findall(Spider.number_pattern, html) # 将一个的number提取出来,格式为[str]
anchor = {'name': name, 'number': number} # 将name 和 number 对应起来,组成一个字典
anchors.append(anchor) # 将这个字典添加到 anchors列表中
return anchors
#
def __refine(self, anchors):
l = lambda anchors: {
'name': anchors['name'][0], #strip() 内置函数,去掉空格
'number': anchors['number'][0] # 取出字符串
}
return map(l, anchors) #{['name':'xxx','number':'yyy']},{['name':'xxx1','number':'yyy1']}...
def __sort(self, anchors): #排序
anchors = sorted(anchors, key=self.__sort_seed, reverse=True) #reverse=True表示降序
return anchors #anchor['number']中的转为float格式,按转化后的数字大小进行排序
def __sort_seed(self, anchor): # 排序调用的方法
r = anchor['number']
if '万' in r:
r = r.strip('万')
r = float(r)
r *= 10000
number = float(r)
return number
def __show(self, anchors): # 显示格式
time_stamp = datetime.datetime.now()
b = str(time_stamp.strftime('%Y.%m.%d - %H:%M:%S') )
with open('./PandaTV主播人气排名.md', 'a') as f:
f.write('\n\n')
f.write(b)
f.write('\n\n')
for rank in range(0, len(anchors)):
a = str(('rank ' + str(rank + 1) + ' ' #加排名,因为是从0开始
'主播姓名' + ':' + anchors[rank]['name'] +
' ' + '观看人数:'+anchors[rank]['number']))
with open('./PandaTV主播人气排名.md', 'a') as f:
f.write(a)
f.write('\n')
def go(self): #主方法
htmls = self.__fetch_content()
anchors = self.__analysis(htmls)
anchors = list(self.__refine(anchors))
anchors = self.__sort(anchors)
self.__show(anchors)
spider = Spider()
spider.go()
附带本次成果