完整代码
1 | from urllib.request import urlopen |
正文
使用re和urllib
1 | from urllib.request import urlopen |
结果显示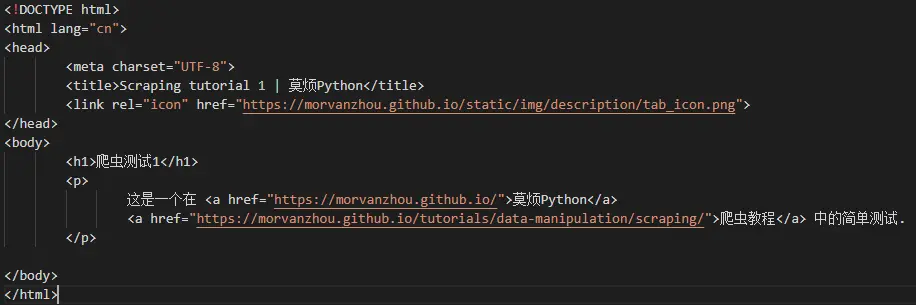
接下来,使用re筛选数据
1 | import re |

1 | res = re.findall(r'href="(.*?)"', html) |

1 | from urllib.request import urlopen |
1 | from urllib.request import urlopen |
结果显示
1 | import re |
1 | res = re.findall(r'href="(.*?)"', html) |