环境信息
使用的 hadoop 完全分布式集群,节点限制,全安装在一起 用户 hadoop
1 | 192.168.2.241 hadoop01 |
spark on yarn, 当前只在 hadoop03 上 安装 spark
spark 安装
官网 https://spark.apache.org/downloads.html
hadoop031
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16wget --no-check-certificate https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgz
mkdir -p /opt/bigdata/spark
tar -zxf spark-3.2.1-bin-hadoop3.2.tgz -C /opt/bigdata/spark
cd /opt/bigdata/spark/
ln -s spark-3.2.1-bin-hadoop3.2 current
chown -R hadoop:hadoop /opt/bigdata/spark/
cat > /etc/profile.d/spark_env.sh<<-eof
export SPARK_HOME=/opt/bigdata/spark/current
export PATH=\$PATH:\$SPARK_HOME/bin
eof
## local 模式测试
spark-submit --master local[2] --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.2.1.jar 100
没问题 则可以 开始使用 spark-cluster 模式,或者 使用 spark on yarn
spark on yarn
- 修改 /etc/hadoop/conf/yarn-site.xml
按需修改1
2
3
4
5
6
7
8
9
10
11
12<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
重启 yarn, ResourceManager, NodeManager 等服务
注意,可能需要
1 | cp ${SPARK_HOME}/yarn/spark-*-yarn-shuffle.jar ${HADOOP_HOME}/share/hadoop/yarn/lib/ |
不然会报错
1 | org.apache.spark.network.yarn.YarnShuffleService not found |
- 开启 Spark 日志记录功能
/opt/bigdata/spark/current/conf/spark-env.sh1
2
3
4
5
6
7export JAVA_HOME=/opt/bigdata/java/current
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/bigdata/hadoop/current/lib/native
export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH
export SPARK_CLASSPATH=$SPARK_CLASSPATH
export HADOOP_HOME=/opt/bigdata/hadoop/current
export HADOOP_CONF_DIR=/opt/bigdata/hadoop/current/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://bigdata/spark-job-log"
/opt/bigdata/spark/current/conf/spark-default.conf
1 | spark.shuffle.service.enabled true |
- 按配置准备好文件
1 | hdfs dfs -mkdir /spark-job-log |
- 启动并验证
1 | cd /opt/bigdata/spark/current/sbin |
- 网页查看
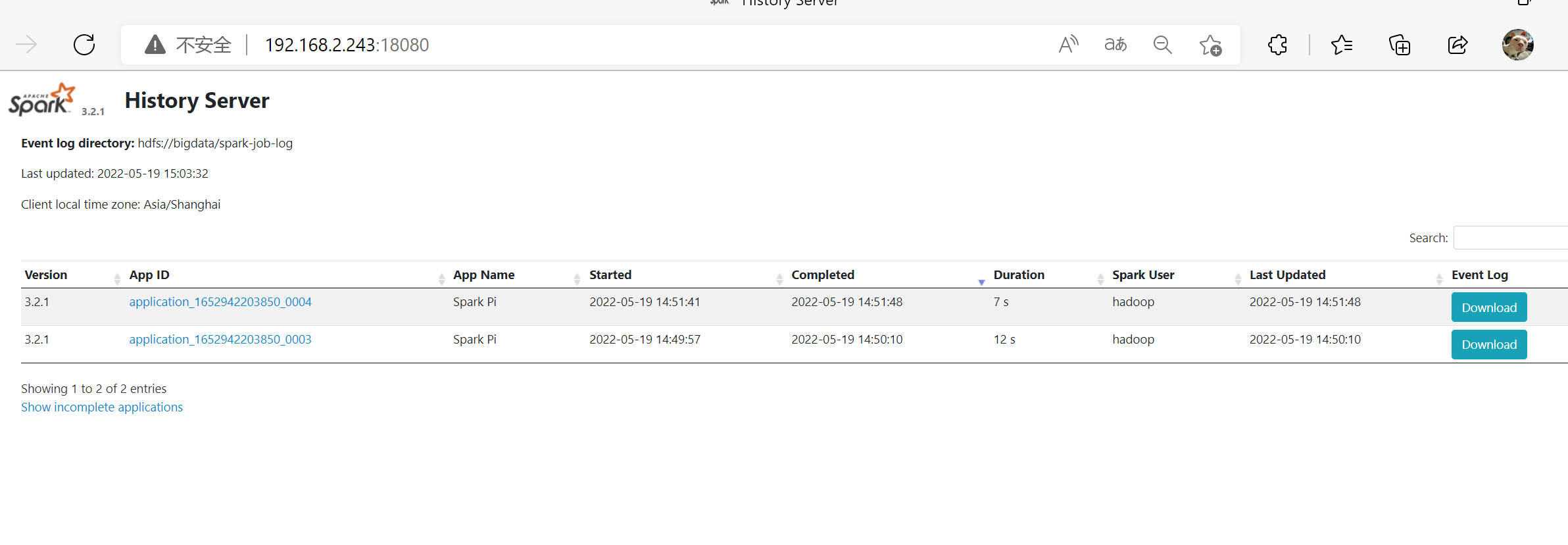
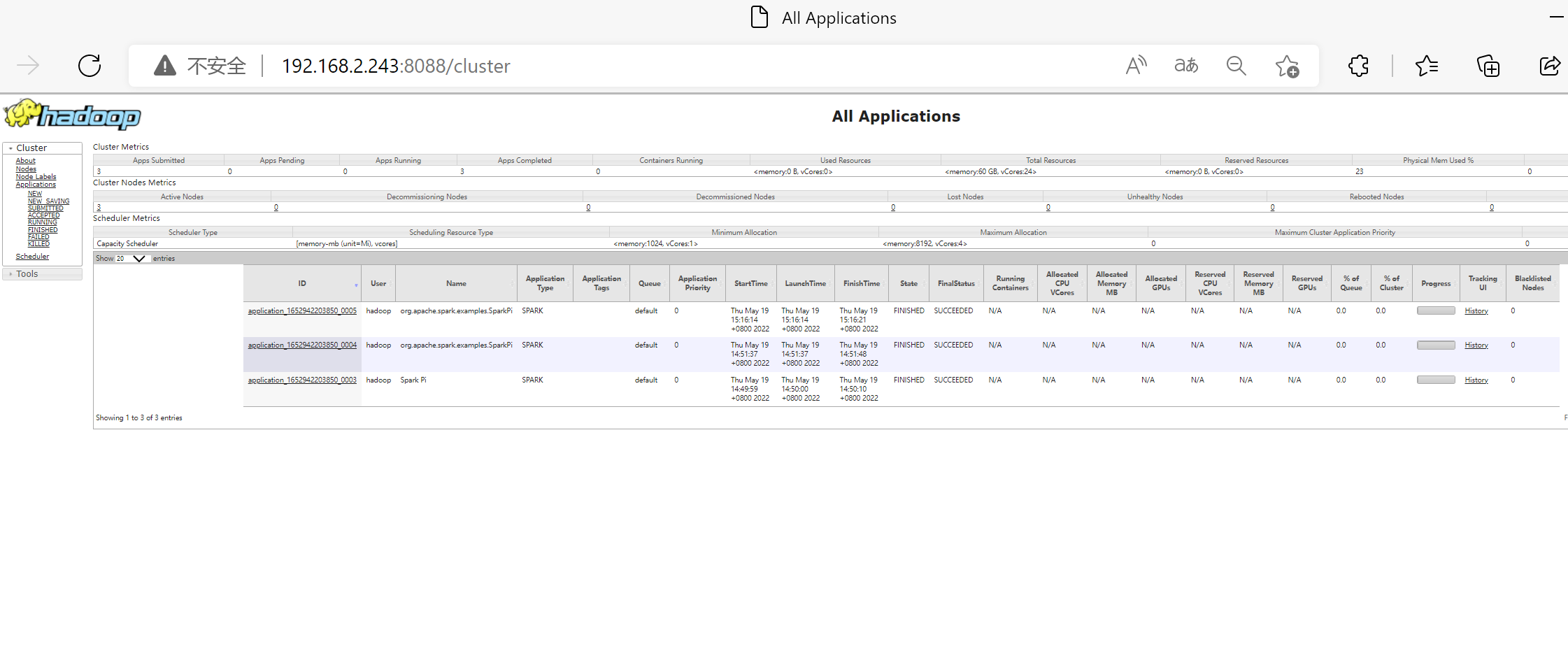
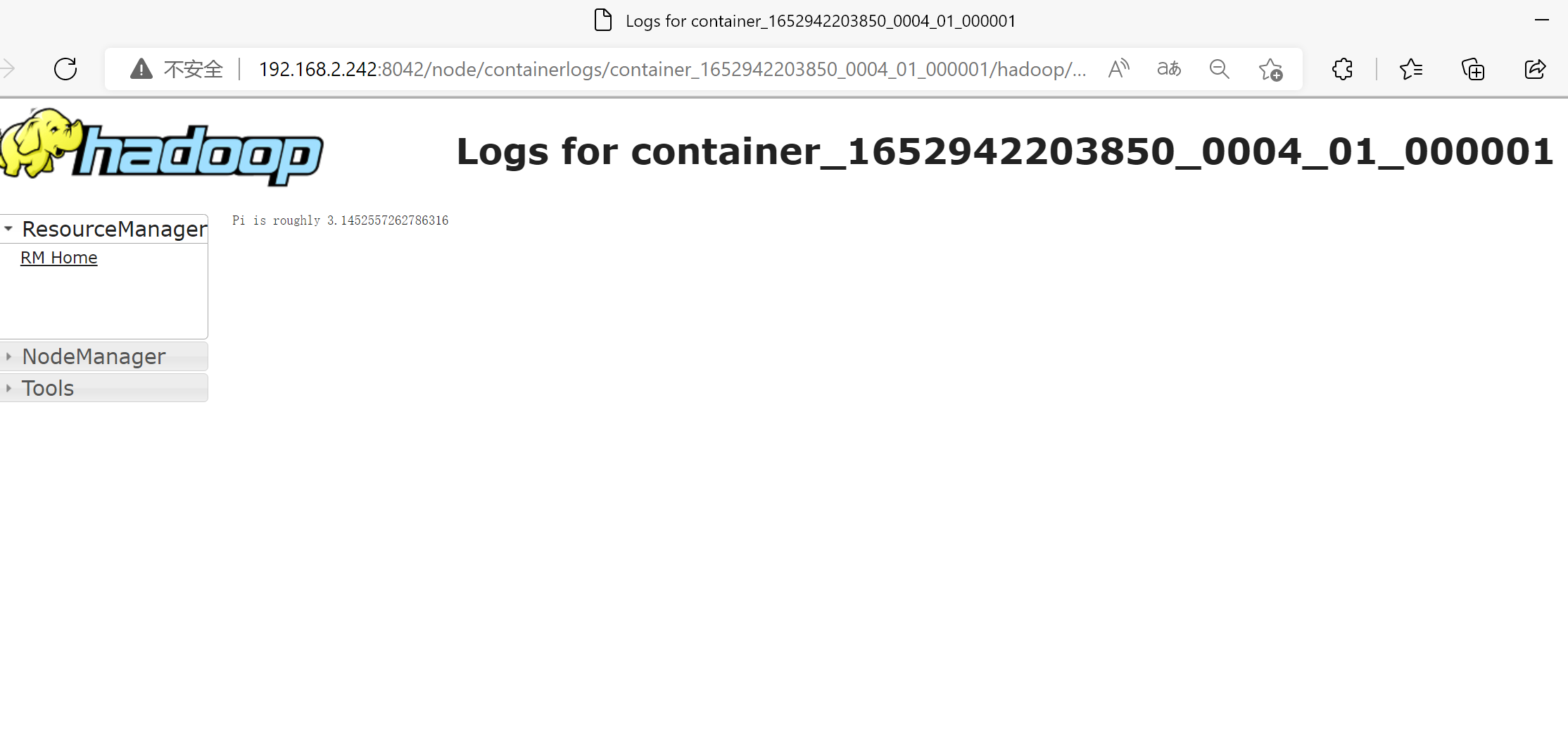
自定义 python 环境
测试代码 /opt/test.py. 都是 在 /opt 目录下执行1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import numpy as np
import jieba
print(np.version.version)
from pyspark.sql import SparkSession
# 创建 SparkSession 并启用 Hive 支持
spark = SparkSession.builder \
.appName("ShowDatabasesExample") \
.enableHiveSupport() \
.getOrCreate()
# 执行 Hive 查询
databases_df = spark.sql("SHOW DATABASES")
# 显示查询结果
databases_df.show()
# 停止 SparkSession
spark.stop()
环境创建
1 | # 创建 Python 3.7.9 环境 |
本地模式
解压
1 | # tar -zxvf pyspark_env.tar.gz -c /opt/ |
修改 spark-env.sh1
2
3export SPARK_SCALA_VERSION=2.12
export SPARK_PRINT_LAUNCH_COMMAND=1
export PYSPARK_PYTHON=/usr/bin/python3
导入环境变量1
2export PYSPARK_PYTHON=/opt/bin/python3
export PYSPARK_DRIVER_PYTHON=/opt/bin/python3
然后执行1
spark-submit --master local test.py
或者 直接指定1
2
3
4
5spark-submit \
--master local \
--conf spark.pyspark.python=/opt/bin/python3 \
--conf spark.pyspark.driver.python=/opt/bin/python3 \
test.py
yarn 模式
上传到 hdfs
1 | hdfs dfs -put pyspark_env.tar.gz /user/test/python_env/ |
客户端模式不需要上传
1 | # 客户端模式 , 本地 conda_python 路径 , 有环境变量可以不用 conf |
其中 #pyspark_env 不能省略,是解压路径
问题
适配 FI 遇到的问题1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{
"ename": "AnalysisException",
"evaluate": "org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassCastException: org.apache.spark.sql.hive.HiveSessionResourceLoader cannot be cast to org.apache.spark.sql.hive.HiveACLSessionResourceLoader",
"execution_count": 0,
"status": "error",
"traceback": [
"Traceback (most recent call last):",
" File \"/opt/spark/python/lib/pyspark.zip/pyspark/sql/session.py\", line 723, in sql",
" return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped",
" File \"/opt/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py\", line 1305, in __call__",
" answer, self.gateway_client, self.target_id, self.name",
" File \"/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py\", line 117, in deco",
" raise converted from None",
"pyspark.sql.utils.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassCastException: org.apache.spark.sql.hive.HiveSessionResourceLoader cannot be cast to org.apache.spark.sql.hive.HiveACLSessionResourceLoader"
]
}
处理方式1
hive-site.xml配置 需要注释hive.security.metastore.authenticator.manager这个配置
spark-hive-yarn-cluster 运行日志
1 | [test@hadoop01 ~]$ spark-submit --master yarn --deploy-mode cluster --conf spark.yarn.dist.archives=hdfs:///user/test/pyspark_env.tar.gz#pyspark_env --conf spark.executorEnv.PYSPARK_PYTHON=./pyspark_env/bin/python --conf spark.executorEnv.PYSPARK_DRIVER_PYTHON=./pyspark_env/bin/python --cnf spark.pyspark.python=./pyspark_env/bin/python --conf spark.pyspark.driver.python=./pyspark_env/bin/python test.py |